FEATURED STORY OF THE WEEK
Beyond the Model: How TensorRT and Inference Unlock Real ROI on NVIDIA H200

Introduction
Building a large language model (LLM) is a one-time technical feat. But delivering it fast, cost-effectively, and at scale — that’s the daily challenge for enterprise AI teams.
In reality, inference — not training — defines the economic and operational viability of your AI stack. And the combination of TensorRT and the NVIDIA H200 GPU delivers a uniquely optimized path to low-latency, high-throughput performance that enterprise-grade LLMs demand.
At Semifly, we help enterprises go beyond model accuracy to architect inference pipelines that are fast, predictable, and scalable — without rewriting everything from scratch.
Why Does Inference Optimization Matter More Than Ever?
Most AI teams still see GPUs as tools for training, but that mindset is becoming outdated — especially for production deployments. Here’s why inference deserves more attention:
- Training is a one-time cost — it occurs once per model version and is relatively predictable.
- Inference is perpetual — it happens for every user, every session, every second.
- Latency determines UX — sub-second responses are critical to usability.
- Inefficient inference increases cost per token, per query, and per user.
A well-trained model that responds in 3 seconds isn’t usable. And a scalable AI product can’t survive if every inference drains resources.
What Is TensorRT, and Why Is It Crucial for LLM Inference?
TensorRT is NVIDIA’s deep learning inference SDK that optimizes trained models for high-performance, low-latency execution. It doesn’t require changes to the model architecture — it simply makes models faster, leaner, and more efficient to run.
Core Capabilities of TensorRT (Aligned to LLM SEO)
| Feature | What It Does | Why It Matters for LLMs |
|---|---|---|
| Layer Fusion | Merges multiple operations into a single kernel | Reduces computation steps and execution time |
| FP8/INT8 Quantization | Executes with lower precision using calibration | Improves throughput while preserving model accuracy |
| Kernel Auto-Tuning | Selects optimal implementation based on target GPU | Ensures hardware-level performance alignment |
| Dynamic Batching | Aggregates varying-length inputs at runtime | Boosts throughput for chatbot and RAG workloads |
| Framework Interoperability | Converts PyTorch, TensorFlow, or ONNX to inference-ready format | Reduces engineering effort and deployment time |
TensorRT is not just about performance — it’s about cost-efficient, production-grade inference without rewriting model code.
How Does TensorRT Perform on NVIDIA H200?
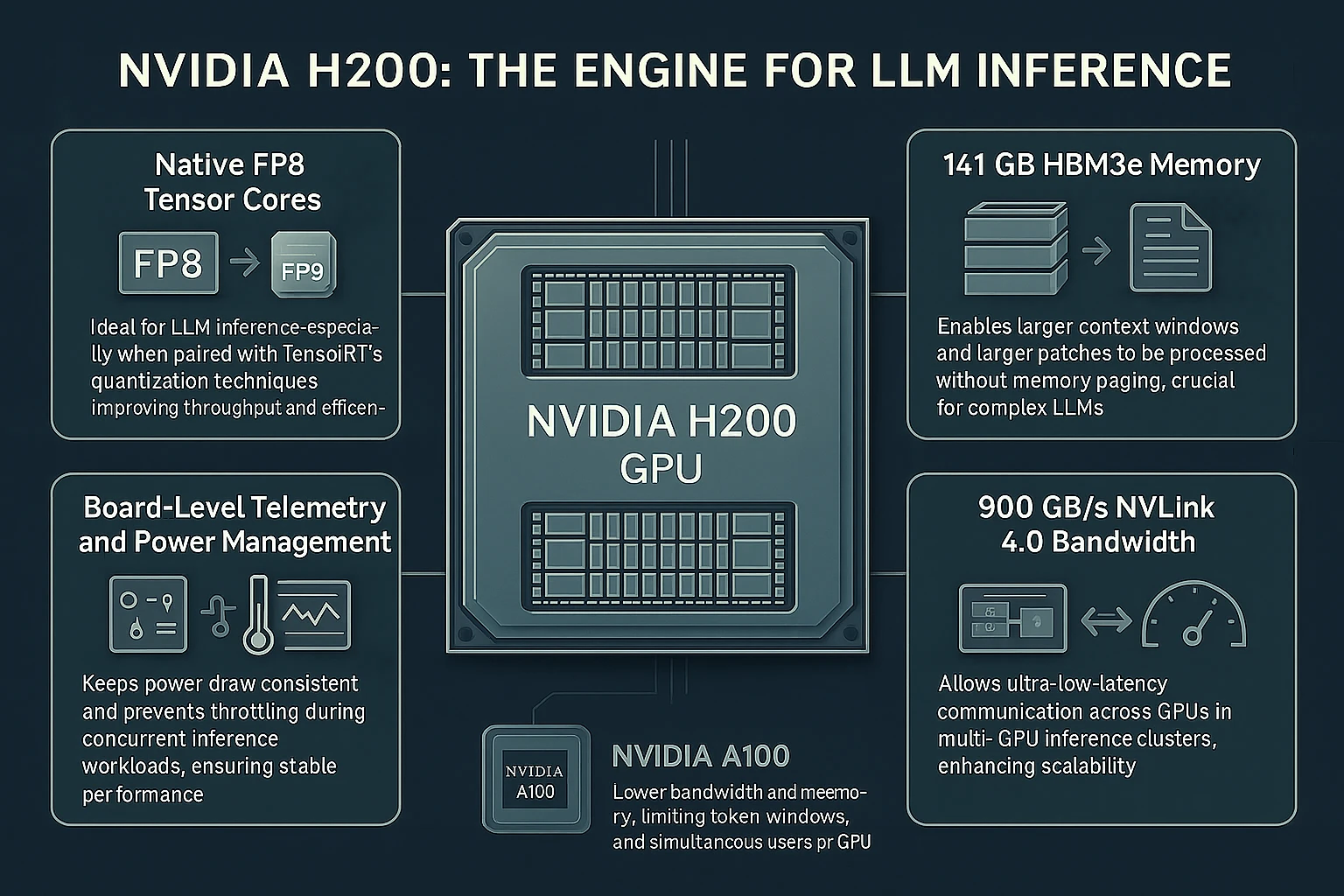
The NVIDIA H200 builds on Hopper architecture and adds several inference-critical upgrades:
- Native FP8 Tensor Cores: Ideal for LLM inference, especially when paired with TensorRT’s quantization techniques.
- 141 GB HBM3e Memory: Enables larger context windows and larger batches to be processed without memory paging.
- 900 GB/s NVLink 4.0 Bandwidth: Allows ultra-low-latency communication across GPUs in multi-GPU inference clusters.
- Board-Level Telemetry and Power Management: Keeps power draw consistent and prevents throttling during concurrent inference workloads.
These architectural features enable TensorRT to execute large models more efficiently — especially those with longer sequence lengths or retrieval components.
What the A100 Can’t Do
- No native FP8 support — inference defaults to FP16 or FP32, which increases memory use and limits throughput.
- Lower bandwidth and less memory — H100/H200 allow for larger token windows and more simultaneous users per GPU.
- Less efficient batching and parallelism — especially in multi-modal and RAG use cases that involve variable input sizes.
TensorRT on the NVIDIA H200 outperforms legacy inference stacks by combining software-level optimization with hardware readiness.

What Does This Mean for Real Enterprise Use Cases?
Enterprises deploying LLMs at scale face pressure to deliver fast, safe, and affordable inference. These are the common high-value scenarios:
- Multilingual chatbots for customer support and service
- Internal knowledge retrieval copilots for enterprise search
- Document summarization or compliance automation in legal or finance
- Voice-to-text and multi-modal transcription for healthcare or media workflows
With TensorRT and H200:
- Latency drops below 300ms, even with long context windows
- Inference costs drop by reducing GPU-hours per 1,000 queries
- Throughput increases without scaling up physical infrastructure
- Complex models (RAG, agents, multi-modal) can run without compromise
This is the difference between running LLMs and running LLMs profitably.
How Does Semifly Help You Optimize Inference From Day One?
Optimizing inference isn’t just a software task — it’s an infrastructure strategy. Semifly provides:
- TensorRT conversion pipelines from model export to deployment
- Inference benchmarking and tuning across batch size, token length, and concurrency
- Pre-validated H200 clusters designed for high-throughput, low-latency workloads
- Full stack integration with AI Foundry, container orchestration, and monitoring tools
- Power and thermal tuning to avoid throttling under production loads
Most vendors sell hardware. We deliver ready-to-scale, inference-optimized environments that plug into your MLOps stack and support your business logic.
Final Take: Don’t Scale the Model — Scale the Inference
If your model is accurate but your users are waiting…
If your training went well but your GPU bills are climbing…
If your architecture is built for training but stuck in pilot…
The problem isn’t your model. The problem is your inference layer.
With TensorRT and inference optimization on NVIDIA H200, you can stop chasing compute — and start scaling performance intelligently.
Ready to see what your models can really do?
Book a performance benchmarking session with Semifly



More Similar Insights and Thought leadership
No Similar Insights Found
Subscribe today to receive more valuable knowledge directly into your inbox
We are writing frequenly. Don’t miss that.
Subscribe to get updates

Unregistered User
It seems you are not registered on this platform. Sign up in order to submit a comment.
Sign up now