

Platform Security Enhancements in Azure: 2026 Update
In the past year, Microsoft has made security its top engineering priority, committing to a company-wide Secure Future Initiative (SFI) and aligning product teams around…
•

High-performance computing (HPC) and AI workloads are increasingly dependent on specialized GPU instructions to handle complex algorithms efficiently. Tasks such as sequence alignment in genomics, shortest path calculations in graph analytics, and matrix-based optimization in AI benefit greatly from hardware-level acceleration. Traditional GPU programming approaches can still leave performance untapped, especially for dynamic programming problems that involve repeated subproblem computations.
NVIDIA’s Hopper architecture addresses this challenge by introducing DPX instructions, specifically designed to accelerate dynamic programming tasks on GPU hardware. These instructions allow researchers and developers to perform essential operations, such as min/max calculations in recursive algorithms, directly on the GPU, significantly reducing computation time and improving throughput. The H200 GPU leverages this capability, enabling organizations to process large datasets and execute high-complexity models faster than ever before.
This blog explores H200 DPX instructions in detail. We will examine how they enhance dynamic programming performance, highlight real-world applications, and provide guidance on best practices for leveraging these instructions in both AI and HPC environments.
Dynamic Programming is a computational method used to solve complex problems by breaking them down into simpler subproblems. Many scientific, engineering, and AI workloads rely on DP for tasks such as sequence alignment in genomics, shortest path calculations in graph analytics, matrix chain multiplication, and various optimization problems. These tasks involve repeated calculations, which can be computationally intensive when handled by standard GPU instructions.
H200 DPX instructions are specialized GPU commands in NVIDIA’s Hopper architecture to accelerate dynamic programming tasks directly on the GPU. By performing operations such as min/max comparisons and cumulative scoring at the hardware level, DPX instructions reduce memory access overhead and improve execution efficiency. This results in faster computation for algorithms that involve large-scale recursion or repeated subproblem evaluations.

The NVIDIA H100 was the first GPU to introduce DPX instructions under the Hopper architecture. It provided a strong foundation for accelerating dynamic programming workloads. The H200 builds on this base with architectural refinements that deliver higher throughput and efficiency, making it better suited for data-intensive AI and HPC environments.
One of the most important differences is memory bandwidth. The H100 uses HBM3 memory, while the H200 is equipped with HBM3e. This upgrade increases available bandwidth significantly, allowing DPX-enabled algorithms to process larger matrices, sequence data, and graph structures without stalling on memory access. For genomics and large-scale optimization problems, this translates directly into faster time-to-results.
The H200 also delivers improved DPX execution efficiency. Instructions such as min/max scoring and recursive updates require fewer cycles compared to the H100. Over billions of iterations, this reduces latency and shortens runtime for algorithms like Smith-Waterman alignment or Floyd-Warshall shortest path calculations.
Another key improvement lies in energy efficiency. The H200 refines concurrency across threads and reduces redundant memory operations, leading to better performance-per-watt. For enterprises and research labs operating large GPU clusters, this means lower operational costs without compromising workload speed.
In short, the H200 retains all the DPX capabilities of the H100 but strengthens them with faster memory, better instruction handling, and improved efficiency. Organizations moving from H100 to H200 can expect measurable gains across all workloads.
High-performance workloads in AI, bioinformatics, and graph analytics often face bottlenecks due to repeated calculations in dynamic programming algorithms. Traditional CUDA kernels can handle these tasks, but require multiple instruction cycles and frequent memory access, which slows execution. The NVIDIA H200 addresses this challenge with DPX instructions that offload key operations directly to the GPU hardware, enabling faster, more efficient processing.
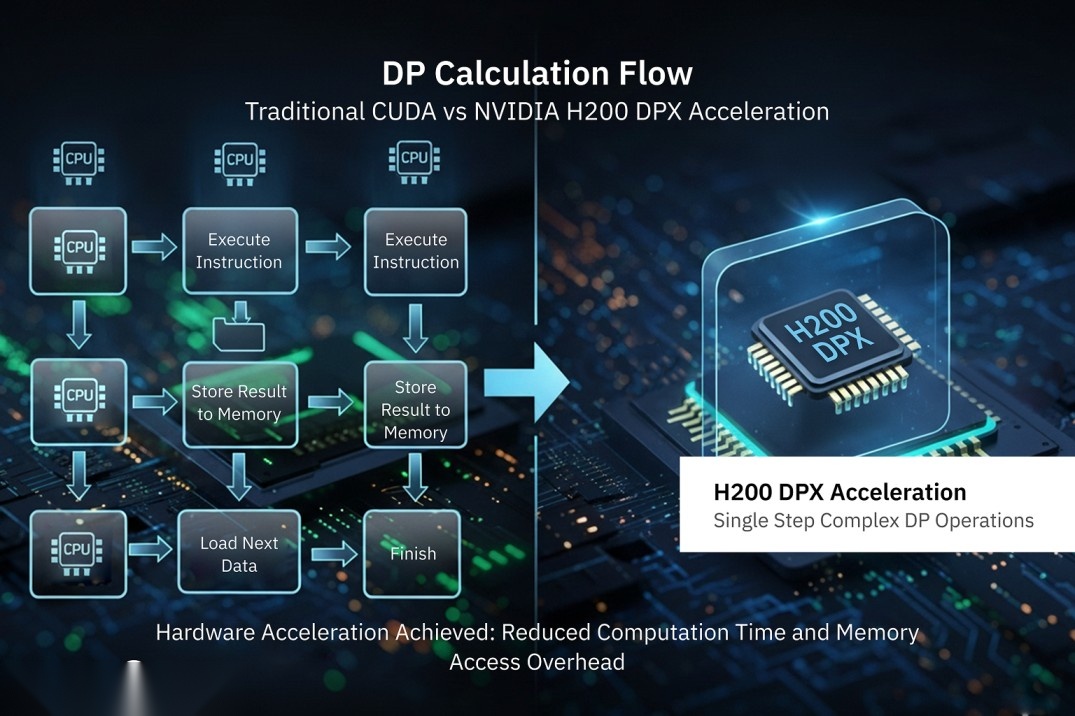
One of the primary benefits of DPX instructions is reduced execution time. In bioinformatics, this translates into quicker genome sequencing runs, where tasks that once required hours can now be completed in minutes. Similar gains have been observed in graph-based workloads, such as shortest path calculations and routing simulations.
Energy efficiency is another advantage. By performing DP operations at the hardware level, the H200 reduces instruction overhead and minimizes data movement between memory and compute units. This leads to lower energy consumption per computation, which is a critical consideration for research institutions and enterprises managing large GPU clusters.
For AI training, DPX instructions accelerate workloads involving recurrent dependencies, such as sequence-to-sequence models or reinforcement learning simulations. Practical benchmarks show that H200 GPUs can train these models significantly faster, allowing researchers and engineers to experiment with larger datasets and deeper architectures without proportional increases in cost or runtime.
The overall outcome is a more efficient platform for handling compute-heavy workloads across multiple domains. By combining higher throughput with reduced energy use, DPX instructions in the NVIDIA H200 deliver measurable performance benefits that directly support both research advancement and enterprise-scale AI adoption.
Dynamic programming is widely used across research and enterprise domains, but has historically been slowed by repetitive calculations and memory bottlenecks. The NVIDIA H200 addresses these challenges with DPX instructions that accelerate common algorithms, enabling breakthroughs in bioinformatics, graph analytics, and optimization. These applications highlight where the H200 provides measurable gains.
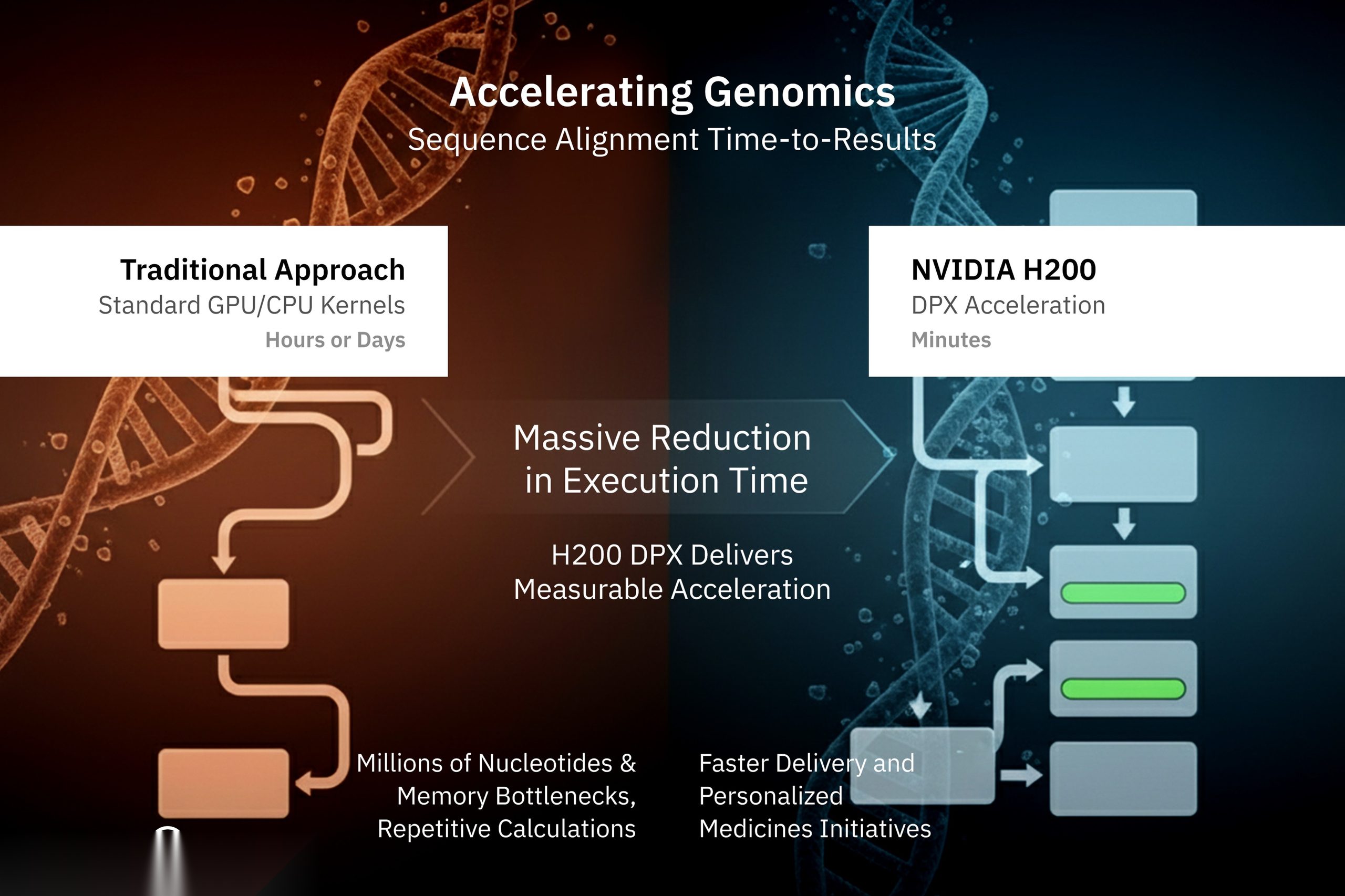
Bioinformatics and Genomics
Genomics research involves computationally intensive tasks such as sequence alignment, protein folding, and genome mapping. These algorithms often compare billions of nucleotide sequences, requiring enormous compute resources. With DPX instructions, tasks like Smith-Waterman sequence alignment can be accelerated significantly compared to CUDA-only implementations. This acceleration allows genome researchers to reduce time-to-results from days to hours, supporting faster drug discovery and personalized medicine initiatives.
Graph Analytics
Graph analytics underpins applications in logistics, communications, and social network analysis. Algorithms such as the Floyd-Warshall shortest path calculation or breadth-first search involve iterative matrix updates that scale poorly on traditional hardware. DPX instructions allow these computations to run more efficiently and deliver faster results. For universities and enterprises, this means faster insights into transportation routing, energy grid optimization, or large-scale knowledge graph exploration.
Optimization Problems
Optimization is a cornerstone of AI, operations research, and high-performance computing. Common tasks include matrix chain multiplication, resource scheduling, and AI planning. These problems are computationally expensive due to the recursive structure of dynamic programming. By handling these operations directly in hardware, H200 DPX instructions deliver much faster computation compared to earlier approaches. This efficiency allows organizations to model larger problem sets and run more iterations within practical timeframes.
H200 DPX instructions can deliver significant acceleration, but reaching peak performance requires careful programming and tuning. Developers need to understand how these instructions interact with CUDA kernels, memory, and thread-level parallelism. Proper design choices at the algorithmic and hardware level ensure that applications make full use of the GPU.
Programming Considerations
DPX instructions are accessed through CUDA, NVIDIA’s parallel programming framework. When writing kernels, developers must structure computations to minimize unnecessary memory transfers and ensure efficient workload distribution across GPU threads. Memory alignment is critical. Misaligned memory can reduce throughput and negate the benefits of DPX acceleration. Instruction-level parallelism—keeping multiple instructions in flight simultaneously—helps maintain high utilization of the GPU’s compute units.
Tiling and Thread Mapping
Dynamic programming algorithms often operate on large grids or matrices. To handle these effectively, DPX workloads should be broken into tiles. Each tile can then be mapped to a group of threads, balancing compute load and memory bandwidth. The goal is to minimize idle threads while ensuring data reuse within shared memory. This tiling approach allows algorithms like sequence alignment or shortest path computations to run at higher throughput.
Profiling and Tuning Workloads
Even with well-structured kernels, performance gaps can occur. Profiling tools such as NVIDIA Nsight Compute provide visibility into thread efficiency, memory bottlenecks, and instruction usage. Developers can identify whether their workloads are limited by compute, memory, or synchronization overhead. CUDA tuning techniques, such as adjusting block sizes or using shared memory effectively, can then be applied to refine performance. These iterative adjustments are essential to achieving the full benefit of H200 DPX instructions.
Best Practices for Developers
By combining careful kernel design with systematic profiling, researchers and developers can ensure that H200 DPX instructions deliver their intended acceleration across bioinformatics, graph analytics, and optimization tasks.
Deploying DPX instructions on the NVIDIA H200 requires both the right hardware and a compatible software environment. Research teams and IT leaders must ensure that their clusters, drivers, and programming tools are fully aligned with Hopper architecture capabilities. Proper deployment planning avoids performance bottlenecks and ensures workloads can scale efficiently.
Hardware Prerequisites
The foundation for DPX acceleration is the NVIDIA H200 GPU, built on the Hopper architecture. This GPU includes specialized tensor cores and DPX units, making it suitable for dynamic programming tasks in genomics, graph analytics, and optimization workloads. To support this hardware, systems must have compatible PCIe or NVLink infrastructure, sufficient cooling, and reliable power delivery. NVIDIA also requires certified drivers that expose DPX instructions at the software layer.
Software Stack
The H200 relies on the CUDA Toolkit, which provides compilers, runtime libraries, and APIs that expose DPX functionality to developers. Optimized libraries, such as cuBLAS and cuDNN, are also being extended to support workloads that benefit from DPX acceleration. Developers must ensure they are using recent versions of the CUDA compiler (nvcc) to generate machine code that can call DPX instructions effectively. NVIDIA’s Hopper Tuning Guide recommends tuning kernel launches and memory tiling to fully exploit these instructions.
Cluster Integration for AI and HPC
For large-scale research or enterprise AI workloads, DPX-enabled GPUs are often deployed in high-performance computing (HPC) clusters. These clusters require interconnect technologies such as NVIDIA NVLink or InfiniBand to maintain high bandwidth and low latency between GPUs and nodes. Efficient job scheduling through resource managers (e.g., Slurm) ensures DPX-enabled kernels run at scale without contention. Enterprises deploying DPX workloads should also consider hybrid environments, combining on-premises GPU clusters with cloud-based GPU instances from providers like AWS or Microsoft Azure.
Deployment Checklist for H200 DPX Workloads
Careful attention to hardware and software requirements ensures that organizations can deploy DPX-enabled workloads reliably. This foundation allows researchers and enterprises to accelerate bioinformatics, graph analysis, and optimization tasks at a scale.
NVIDIA H200 GPUs with DPX instructions provide significant acceleration for dynamic programming workloads by executing compute-intensive operations directly in hardware. This leads to measurable improvements in speed and efficiency, enabling research teams and enterprises to process larger datasets, shorten experiment turnaround times, and reduce operational costs.
To fully leverage DPX capabilities, developers must understand the instruction model, optimize CUDA kernels, and profile workloads with tools such as NVIDIA Nsight. With this technical discipline, organizations can achieve higher throughput, support more complex models, and deliver faster AI and HPC results. As datasets grow, instruction-level performance will increasingly influence research efficiency, making the H200 platform with DPX a key enabler for advanced computational projects.





We are writing frequenly. Don’t miss that.

Unregistered User
It seems you are not registered on this platform. Sign up in order to submit a comment.
Sign up now