FEATURED STORY OF THE WEEK
User-Driven Security Practices for NVIDIA DGX H100/H200 Deployment

Imagine guarding a vault holding $12 million in assets. That’s the reality when securing NVIDIA DGX H100 and H200 systems running cutting-edge AI models. Yet IBM’s 2024 report reveals a harsh truth: 68% of infrastructure breaches start with misconfigured user settings. This isn’t a flaw in the hardware – NVIDIA builds robust protections into every DGX. The vulnerability emerges after deployment, where user decisions determine real-world safety.
While NVIDIA provides essential security foundations like Hardware Root of Trust and encrypted storage, these alone aren’t enough. Like buying a high-security safe but leaving the combination on a sticky note, default protections only work when users actively reinforce them. Your network configurations, access controls, and data handling practices form the critical outer layers that shield your AI investments from theft, sabotage, or compliance failures.
This is “user-driven security”: the policies you implement beyond factory settings to lock down GPU clusters. It means treating every DGX node as a high-value target and proactively hardening it against evolving threats.
In this guide, we’ll transform that responsibility into actionable steps, because in AI infrastructure, security isn’t just a feature. It’s a practice you own daily.
Foundational Security Posture
Before implementing advanced protections, understand what NVIDIA provides out-of-the-box and where your responsibility begins. This foundation sets the stage for user-driven security actions.

A. DGX H100/H200’s Built-In Protections
NVIDIA equips DGX H100 and H200 systems with critical hardware security starting at the factory. The Hardware Root of Trust (HRoT) acts like a unique digital fingerprint. It verifies that every component—from BIOS to firmware—is authentic and unmodified during boot, blocking compromised parts.
Complementing this, the BlueField-3 DPU (Data Processing Unit) operates as a security co-processor. It handles network encryption, scans traffic for threats, and enforces access rules before data reaches the GPUs, reducing attack surfaces.
| Layer | Default Protection | User Responsibility |
|---|---|---|
| Firmware | HRoT verifies boot integrity | Regular attestation checks |
| Network | Basic firewall rules | Zero Trust microsegmentation |
| Data | Automatic at-rest encryption | In-transit TLS/SSL controls |
B. Threat Modeling for AI Systems
AI infrastructure faces unique risks beyond traditional servers:
- Model Theft: Attackers targeting trained AI models (valued at millions) stored in GPU memory.
- Data Poisoning: Malicious tampering with training data to corrupt AI behavior (e.g., inserting biased images).
- Adversarial Attacks: Specially crafted inputs that trick AI into misclassifying data—like making a self-driving car ignore stop signs.
Together, these threats create a risk landscape, necessitating defenses that span hardware encryption, data lineage verification, and runtime model shielding.
2. User-Driven Security Practices
These actionable steps bridge the gap between NVIDIA’s defaults and enterprise-grade security for your DGX H100 and H200 systems:
Practice 1: Hardware Hardening
A. Disabling Unused Access Points
Users should deactivate non-essential physical interfaces, including:
- IPMI (Intelligent Platform Management Interface): A remote management service vulnerable to “out-of-band” attacks if unsecured.
- USB ports: Potential vectors for physical malware installation or unauthorized data extraction.
Disabling these interfaces reduces attack surfaces significantly in enterprise environments.
B. Enforcing Secure Boot
System administrators must enable Secure Boot in the DGX BIOS (Setup > Security > Secure Boot). This security function acts as a gatekeeper, permitting only NVIDIA-verified firmware and software components to execute during system initialization. Unauthorized or unsigned code is systematically blocked from loading.
C. Implementing TPM-Based Attestation
The Trusted Platform Module (TPM)—a dedicated cryptographic processor—should be configured for continuous hardware integrity validation. This process operates as follows:
- The TPM generates real-time measurements of system state
- Measurements are cryptographically compared against NVIDIA’s trusted baseline
- Access is automatically revoked if deviations indicate compromise.
This mechanism detects firmware tampering or bootloader exploits that could compromise AI workloads.
Practice 2: Zero Trust Networking
Why Zero Trust Matters for DGX Systems
Traditional network security models operate on a dangerous assumption: once devices pass perimeter defenses, they’re trusted to communicate freely within the network. This “trust but verify” approach becomes catastrophic in AI infrastructure like NVIDIA DGX H200 clusters, where high-value assets and interconnected architectures create unique vulnerabilities.
A single compromised node—whether through credential theft or malware—can expose proprietary models worth millions, turning GPU-accelerated workflows into lucrative targets.
The problem intensifies with the very design of AI infrastructure. High-speed GPU-to-GPU communication channels like NVLink or InfiniBand, essential for distributed training, inadvertently create an “attack highway.” Attackers exploit these pathways for lateral movement, enabling rapid traversal across nodes to exfiltrate models or deploy ransomware. What makes this especially perilous is that conventional security tools often lack visibility into these specialized interconnects.
Zero Trust architecture dismantles this vulnerability by rejecting implicit trust entirely. Its core principle—”never trust, always verify”—mandates rigorous authentication and microsegmentation for every connection attempt, whether from external actors or between internal nodes.
By treating all traffic as potentially hostile, Zero Trust ensures that even breached components are contained. This prevents catastrophic horizontal spread across your DGX fabric.

Implementation Framework
A. Microsegmentation for GPU Nodes
Critical to Zero Trust implementation is microsegmentation, where the DGX H200 cluster is divided into isolated security zones. This granular segmentation enforces strict communication boundaries where training nodes cannot initiate connections to inference servers. This prevents compromised research workloads from impacting production models.
Similarly, storage systems housing sensitive datasets are configured to accept connections only from authorized GPUs within designated segments, not broad IP ranges.
Each microsegment operates under customized firewall rules tailored to its specific function, such as blocking unnecessary NVLink traffic between unrelated GPU groups or restricting access to Kubernetes control planes. This containment strategy transforms your AI fabric from a flat risk zone into compartmentalized security enclaves.
B. Service Mesh Authentication
Traditional networks inherently trust east-west traffic, creating dangerous vulnerability chains where compromised services can impersonate legitimate ones. To overcome this, deploy service mesh tools like Istio or Linkerd that issue cryptographic identities to every service—whether a data loader, model trainer, or inference endpoint.
These identities enable mutual TLS (mTLS) encryption for all service-to-service communication, rendering intercepted traffic useless to attackers. Crucially, credentials are validated before every request—not just at the initial connection—ensuring continuous verification. This “never trust, always authenticate” approach neutralizes lateral movement threats that bypass perimeter defenses.
Admin Access Control Template
The YAML configuration below enforces Zero Trust for administrative access:

Practice 3: Secure Container Orchestration
Containers accelerate AI deployment but introduce unique risks in GPU environments. These can be mitigated through:
A. GPU-Aware Pod Security Policies
Traditional Kubernetes security policies lack granular control over GPU resources, creating critical vulnerabilities in AI infrastructure. Default configurations permit a single compromised pod to monopolize all available GPUs—enabling resource hijacking for cryptomining or denial-of-service attacks.
More dangerously, containers gain unrestricted access to underlying NVIDIA drivers and devices, allowing malicious actors to manipulate firmware interfaces or exploit privileged operations. These blind spots transform GPU nodes into high-risk assets where AI models and sensitive data face exposure.
GPU-aware Pod Security Policies address this gap by introducing hardware-specific safeguards. They enforce rules like per-pod GPU limits, driver access restrictions, and read-only filesystems. This extends Kubernetes’ native security model to understand accelerated compute environments.
This specialized layer prevents unauthorized resource consumption while blocking pathways to driver-level compromises. This establishes essential containment for high-value AI workloads.
Implementation Template:

Key Controls:
| Rule | Threat Mitigated | Compliance Alignment |
|---|---|---|
| nvidia.com/gpu: 1 | Resource hijacking | NIST AI RMF SC-6 |
| readOnlyRootFilesystem | Malware persistence | HIPAA §164.312(a)(1) |
| allowedHostPaths | Driver manipulation | ISO 27001 A.8.19 |
B. Encrypted GPU Memory
Direct Memory Access (DMA) attacks can extract AI models from GPU RAM using tools like PCIe sniffers. This issue can be fixed with encryption.
How Encryption Works in H100 and H200:

Activation Commands:

Use Cases Requiring Encryption:
- Healthcare: Protecting patient-derived AI models (HIPAA)
- Defense: Classified image recognition workloads
- Finance: Fraud detection models with PII data
Practice 4: Data Governance Controls
Why Traditional Data Security Fails for AI
AI workflows fundamentally break conventional data protection models by introducing three catastrophic risks: training datasets frequently ingest sensitive personally identifiable information (PII) and protected health records (PHI) that legacy systems aren’t designed to safeguard during distributed processing.
Simultaneously, the trained models themselves become high-value theft targets, often worth millions in intellectual property, yet remain exposed in GPU memory where traditional encryption fails. These vulnerabilities collide with stringent regulations like GDPR and CCPA, which impose fines for breaches involving unauthorized data exposure.
Many AI compliance violations directly stem from this governance gap—where organizations apply outdated “perimeter-and-encryption” tactics to workflows demanding dynamic, context-aware protection.
Unlike static databases, AI data pipelines require continuous governance that adapts to real-time processing across GPUs, networks, and storage tiers—a paradigm shift traditional tools cannot deliver.
Critical Security Measures
A. Tokenization of Training Data
Traditional approaches to data protection collapse when applied to AI training pipelines, where raw sensitive information like Social Security numbers or medical records becomes a compliance liability and theft target.
Tokenization solves this by replacing original data with algorithmically generated tokens—preserving structural utility while eliminating exposure.
The process follows a secure workflow: raw data such as “SSN 123-45-6789” enters a tokenization engine (e.g., NVIDIA NeMo integrated with Azure Key Vault), which outputs non-sensitive tokens like “TK-9X2Y4Z” for model training.
Crucially, detokenization occurs only in secured environments post-processing, ensuring sensitive values never reside in GPU memory during computation.
Implementation leverages purpose-built libraries that maintain data format integrity, critical for preserving feature relationships in datasets:
Tokenization Solution:

Implementation:

This approach delivers three transformative advantages: original data never enters vulnerable GPU memory during training; stolen tokens remain useless without access to heavily guarded vaults; and structural consistency enables uninterrupted model learning while satisfying GDPR/CCPA pseudonymization requirements.
B. Watermarking AI Models with NVIDIA Morpheus
The theft of proprietary AI models can result in stolen models surfacing in competitor products or black markets. NVIDIA Morpheus counters this through sophisticated watermarking that embeds indelible ownership signals without impacting model performance. The workflow begins by injecting covert identifiers—like statistical noise patterns or trigger samples—during model finalization:
Morpheus Watermarking Workflow:

Three forensic watermarking techniques serve distinct purposes:
- Noise Injection inserts imperceptible signal variations detectable through statistical analysis, enabling covert tracking of stolen models in the wild.
- Trigger Samples embed unique input-output relationships (e.g., specific image → anomalous classification) that serve as court-admissible evidence.
- API Fingerprinting identifies stolen SaaS models by analyzing call pattern signatures during inference.
When watermarked models execute—whether in legitimate deployments or illicit copies—Morpheus triggers automated detection:
– name: “Detection”
trigger: “model_inference”
action: “alert_legal_team” # Initiates forensic investigation
This approach delivers unparalleled forensic value: watermarks withstand model fine-tuning and compression while providing legally actionable proof of ownership.
Practice 5: Identity and Access Management
The Critical Access Risks in AI Environments
H100 and H200 systems confront unprecedented identity threats that amplify security and compliance exposure. Static SSH keys—often valid for 450 days or more—create perpetual attack vectors, allowing stolen credentials to persist undetected for months.
Compounding this, overprivileged users routinely access sensitive models and datasets far beyond their operational needs, turning legitimate accounts into insider threats.
These vulnerabilities collide with escalating regulatory mandates like GDPR and India’s DPDP Act, which impose severe penalties for improper access controls. This makes credential hygiene and least-privilege access non-negotiable imperatives.
Security Implementation Guide
A. Time-Bound SSH Certificates
Traditional SSH keys create critical vulnerabilities by remaining valid indefinitely—often for 450+ days. This allows attackers infinite access if compromised. The solution replaces static keys with dynamically generated certificates that automatically expire after a defined period (typically 1-24 hours).
Implemented through centralized authorities like HashiCorp Vault, this approach follows a secure workflow: administrators request short-lived certificates (vault ssh -role=dgx-admin -ttl=1h sign admin@dgx-01), then access nodes via ephemeral credentials (ssh -i cert.pem admin@dgx-01).
This architecture delivers three key advantages: certificates self-destruct post-expiration, eliminating persistent attack surfaces; private keys never reside on admin devices, thwarting endpoint theft; and centralized revocation enables instant response to compromised identities.
Solution Architecture:
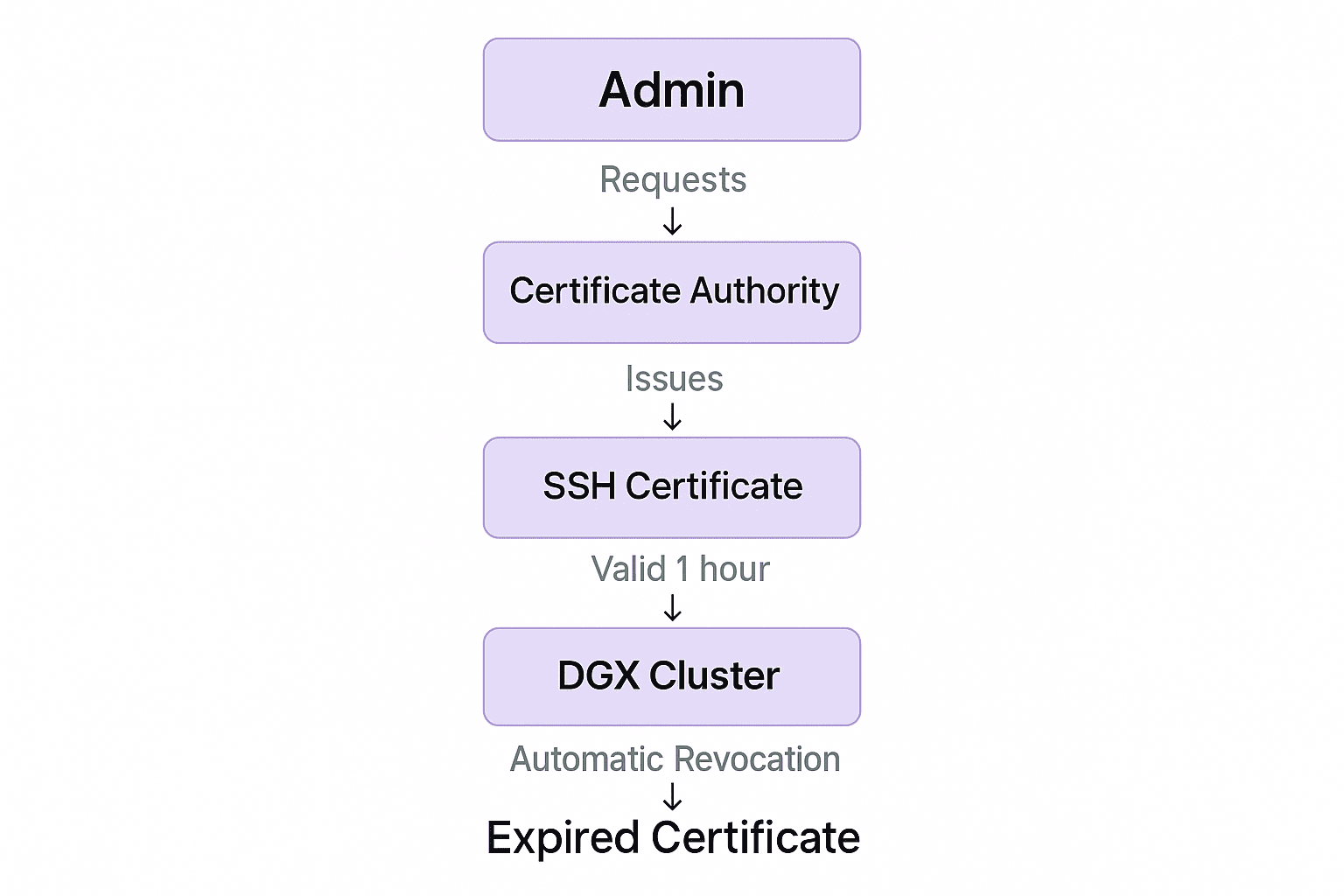
Implementation:

B. RBAC with NVIDIA AI Enterprise
NVIDIA AI Enterprise introduces granular role-based controls tailored to AI workflows, where overprivileged access risks model theft and regulatory violations. The framework enforces least-privilege through declarative policies:
Granular Access Control Framework:

Key Controls:
| RBAC Element | Security Function | Compliance Alignment |
|---|---|---|
| gpu_quota | Prevents resource hijacking | NIST AI RMF AC-6 |
| models restriction | Limits sensitive model access | HIPAA §164.312(a)(1) |
| mfa_required | Enforces strong authentication | ISO 27001 A.9.4.2 |
? Implementation Tip: Integrate with Okta/Azure AD for enterprise SSO.
Practice 6: Continuous Threat Monitoring
Conventional security monitoring tools fail catastrophically in AI infrastructure because they cannot interpret the unique threat patterns exhibited by GPU-accelerated workloads. Abnormal GPU utilization—such as high compute loads during off-peak hours—signals cryptojacking or model theft attempts, yet traditional systems dismiss this as “expected high usage.”
More critically, high-speed InfiniBand networks enable silent data exfiltration at 100Gb/s+, bypassing standard network sensors that lack visibility into GPU-direct RDMA traffic. These blind spots converge with sophisticated zero-day attacks targeting NVIDIA CUDA kernels, where malicious payloads exploit vulnerabilities in parallel processing operations that conventional IDS/IPS solutions cannot parse.
This trifecta of undetectable threats—resource hijacking, invisible data theft, and kernel-level compromises—creates a perfect storm where most AI breaches persist undetected for days.
Unlike traditional IT systems, DGX clusters demand specialized telemetry capturing GPU memory access patterns, InfiniBand metadata, and CUDA kernel integrity checks—data dimensions entirely absent from legacy security tools.
The Visibility Gap in Practice
| AI-Specific Threat | Why Traditional Tools Miss It | Consequence |
|---|---|---|
| GPU Cryptojacking | Treat 100% utilization as “normal” | $50K/month in power/theft |
| InfiniBand Exfiltration | Can’t decrypt RDMA traffic | 10GB/s model theft in 1 sec |
| CUDA Kernel Exploits | No runtime kernel behavior analysis | Full cluster compromise |
Advanced Monitoring Framework
A. Prometheus Alerts for GPU Anomalies
Traditional monitoring systems lack the context to detect AI-specific attacks, making targeted alert configurations essential. Implementing GPU-aware Prometheus alerts enables real-time detection of malicious patterns:
- Cryptojacking Detection: Triggers when GPU utilization exceeds 95% and power draw surpasses 300W for 5+ minutes (avg(nvidia_gpu_duty_cycle) > 95% and nvidia_gpu_power_draw > 300W), signaling unauthorized cryptocurrency mining.
- Model Exfiltration Alerts: Flags abnormal memory copy rates exceeding 10GB/s with asymmetric network traffic (rate(nvidia_gpu_mem_copy_bytes[5m]) > 10GB/s and nvidia_gpu_pcie_tx_bytes > nvidia_gpu_pcie_rx_bytes * 5), indicating theft of high-value AI models.
Critical metrics demanding continuous surveillance include:
- nvidia_gpu_duty_cycle (threat >95% sustained)
- nvidia_gpu_mem_copy_bytes (exfiltration >10GB/s)
- nvidia_gpu_power_violation (hardware tampering >0)
These thresholds transform raw telemetry into actionable security intelligence, shrinking detection time from weeks to minutes.
Critical Alert Templates:

B. NVIDIA DOCA Telemetry Pipelines
The DOCA framework on BlueField-3 DPUs establishes a real-time threat intelligence pipeline that captures:
- GPU memory access patterns
- InfiniBand traffic metadata
- PCIe/DMA activity
- Fabric controller events
Real-Time Threat Intelligence Flow:

Implementation leverages low-level C code for precision data collection:

This approach delivers three revolutionary advantages over traditional monitoring:
- Near-zero overhead: Runs exclusively on DPUs, preserving GPU cycles for AI workloads
- Encrypted traffic analysis: Inspects encrypted RDMA traffic without decryption
- Hardware-rooted visibility: Detects DMA attacks and PCIe-level exploits invisible to OS-based tools

SIEM Integration Framework
Optimized Schema for AI Threat Detection:

Compliance Alignment
| Regulation | Monitoring Requirement | DOCA Implementation |
|---|---|---|
| NIST AI RMF | Real-time model access logging | GPU memory access telemetry |
| GDPR Art 32 | Breach detection <72hrs | Automated SOC alerts |
| HIPAA §164.312 | Audit controls for ePHI | Immutable DOCA event logs |
Practice 7: Incident Response Playbooks
Why Standard IR Playbooks Fail for AI
Ransomware targeting DGX clusters represents a paradigm shift that renders traditional incident response playbooks obsolete. Unlike conventional attacks focused on data encryption, AI ransomware prioritizes model theft—exfiltrating proprietary models before triggering encryption as a distraction.
This dual-threat approach exploits a critical gap: traditional forensics tools cannot capture volatile GPU memory artifacts where models reside during training/inference, allowing thieves to disappear with intellectual property before defenders react.
Compounding this, the financial impact of DGX downtime escalates exponentially. Yet, standard IR procedures require hours to initiate containment.
Meanwhile, attackers leverage high-speed InfiniBand networks to steal 100GB+ models in under 10 seconds. CrowdStrike’s 2024 report confirms the accelerating threat: AI-targeted ransomware attacks surged 317% year-over-year, with 83% of incidents involving concurrent model theft and encryption.
These factors converge into a perfect storm where legacy playbooks fail at every phase: they cannot preserve GPU memory evidence, lack protocols for rapid fabric isolation, and underestimate the strategic value of preemptive model recovery over post-attack decryption.
DGX-Specific Containment Protocol
AI infrastructure demands specialized containment strategies that outpace the conventional incident response. The first 10 minutes determine whether attackers steal models or are neutralized—requiring automated, hardware-enforced isolation rather than manual intervention.
This protocol prioritizes evidence preservation alongside threat containment, recognizing that DGX incidents demand forensic readiness equal to operational recovery.
Critical First 10 Minutes:
The containment sequence executes autonomously upon threat detection, leveraging NVIDIA’s hardware-integrated security controls. This orchestrated response physically isolates compromised elements while freezing evidentiary states—transforming passive defense into active protection of high-value AI assets. Unlike traditional networks, DGX clusters require sub-second actions coordinated across InfiniBand, DPUs, and GPUs to prevent irreversible IP loss.
Step-by-Step Containment:
InfiniBand/NVSwitch Disconnection:

Why this Matters: Most AI ransomware spreads laterally through high-speed interconnects within 90 seconds. Disabling these pathways is non-negotiable for containment. This hardware-level isolation prevents attackers from jumping to backup nodes while preserving pre-attack network state for forensic analysis.
DPU Network Lockdown:

Critical Function: Blocks live command-and-control traffic without disrupting evidentiary packets stored in DPU buffers. This unique capability maintains forensic integrity while neutralizing active threats—impossible with software firewalls that alter attack signatures.
GPU Memory Preservation:

Preservation Imperative: Captures model weights, attacker toolkits, and encryption keys residing in volatile GPU RAM. This snapshot freezes the digital crime scene before attackers wipe evidence—critical for post-incident attribution and model recovery that traditional memory dumps miss entirely.
BlueField DPU Forensic Capture
The DPU becomes a forensic command center during incidents, leveraging its isolated position between networks and GPUs. Unlike host-based tools compromised during attacks, the DPU’s hardware-rooted trust provides uncontaminated evidence critical for understanding sophisticated breaches. This transforms a security component into an active forensic asset during crises.
Evidence Collection Workflow:

Step 1: Secure DPU Memory Capture

Forensic Advantage: Preserves attacker tools and connection logs in DPU cache memory that would be overwritten during reboot. This low-level capture includes encrypted traffic decryption keys and firmware manipulation attempts invisible to OS-level forensics.
Step 2: Network Traffic Reconstruction

Evidence Breakthrough: Reconstructs InfiniBand exfiltration sessions without decryption by analyzing flow metadata. This bypasses legal barriers to encrypted traffic inspection while providing court-admissible proof of data theft vectors and destinations.
Step 3: Attack Timeline Generation

Investigative Power: Correlates DPU telemetry, GPU memory snapshots, and host logs into an immutable attack narrative. This automated timeline meets NIST 800-86 forensic standards while accelerating breach analysis from days to minutes—critical for regulatory reporting windows.
Summing Up: Building Your Security Workflow
Securing NVIDIA DGX H100 and H200 systems requires proactive measures that extend far beyond factory settings. By implementing critical user-driven practices—hardware lockdown, Zero Trust segmentation, container safeguards, data governance, access control evolution, continuous monitoring, and incident readiness—you create layered defenses that transform vulnerable AI infrastructure into a resilient foundation. These protocols collectively neutralize attack vectors across physical, network, and application layers while ensuring regulatory alignment.
This comprehensive approach doesn’t just protect assets; it redefines your AI infrastructure as a trustworthy engine for innovation—where security becomes an enabler rather than an obstacle.



More Similar Insights and Thought leadership
No Similar Insights Found
Subscribe today to receive more valuable knowledge directly into your inbox
We are writing frequenly. Don’t miss that.
Subscribe to get updates

Unregistered User
It seems you are not registered on this platform. Sign up in order to submit a comment.
Sign up now