FEATURED STORY OF THE WEEK
Why Llama2 70B Runs Better on H200

Why Llama2 70B Runs Better on H200-Architecture, Throughput, and Practical Gains

1. The Elephant in the Room: Why Llama2 70B Strains GPUs
Running large AI models like Llama2 70B pushes GPUs to their limits. With 70 billion parameters, the model demands massive resources that overwhelm traditional hardware. This creates real deployment challenges for businesses and developers.
The model’s complex design intensifies these demands. Its specialized calculation units work in parallel to understand language context. But this power comes at a cost: generating responses requires building a temporary Key-Value (KV) Cache – a conversation memory that grows rapidly with longer chats or documents. Research shows this cache alone can consume over 60GB of memory during operation.
Traditional GPUs hit two critical bottlenecks:
- VRAM Capacity Limits: Most high-end GPUs (like NVIDIA’s 80GB H100) can’t store the entire 140GB model plus its growing KV cache. When full, systems resort to offloading: moving data to a slower CPU or system RAM. This causes major delays.
- Memory Bandwidth Starvation: Even when data fits, GPUs struggle to deliver it fast enough to computing cores. The H100’s 3.35TB/s bandwidth becomes a bottleneck, leaving processors idle while waiting for model weights and context data.
These limitations create tangible problems:
- High Latency: Slow response times frustrate users.
- Low Throughput: Fewer queries processed per second.
- Instability: Crashes or slowdowns during long conversations.
This “elephant in the room” forces compromises: smaller models, reduced context, or expensive multi-GPU setups – until now.
2. Enter the H200: Architecture Tailored for Giant Models
The NVIDIA H200 represents a breakthrough in GPU design specifically engineered for massive AI models like Llama2 70B. Its innovations solve the core memory limitations that hampered previous hardware through two key advancements.
Core Innovation: HBM3e Memory
The H200 uses HBM3e memory, the fastest GPU memory technology available. It delivers 4.8 TB/s of bandwidth. That’s 40% faster than the H100’s 3.35 TB/s. Bandwidth determines how quickly the GPU can access its “working memory.” Higher bandwidth means less waiting for data. This is critical for feeding Llama2 70B’s parameters to processing cores without delays.
Unprecedented 141GB Capacity
With 141GB of memory, the H200 can store Llama2 70B’s entire 140GB parameter set and its dynamic context memory. The H100’s 80GB memory forced systems to offload data to slower system RAM during operation. This caused major slowdowns. The H200 eliminates this bottleneck entirely by keeping everything in high-speed GPU memory.
Hopper Architecture Refinements
Beyond raw memory, the H200 enhances NVIDIA’s Hopper architecture:
- Enhanced Tensor Cores: Specialized units that accelerate AI math operations. They now better support FP8 precision, an 8-bit format that doubles speed while maintaining accuracy.
- Optimized Memory Controllers: Improved hardware pathways that maximize HBM3e’s 4.8 TB/s bandwidth. This ensures data flows efficiently to processors.
- Larger 50MB L2 Cache: Acts as a “quick-access shelf” for frequently used data. This benefits operations like attention calculations in frameworks like TensorRT-LLM.
| Feature | H200 Advantage | Impact on Llama2 70B |
|---|---|---|
| HBM3e Bandwidth | 4.8 TB/s (40% > H100) | 2.3x faster weight loading |
| Memory Capacity | 141GB vs 80GB (H100) | Full model + large batches in VRAM |
| FP8 Support | 2x faster matrix math | Double tokens/sec with optimization |
| L2 Cache | 50MB (vs 40MB on H100) | Faster attention computations |
3. Synergy in Action: How H200 Features Directly Accelerate Llama2 70B
The H200’s hardware innovations unlock unprecedented performance when paired with real-world workloads. Here’s how its capacity, bandwidth, and software synergy overcome Llama2 70B’s limitations.
Capacity Wins: No More Compromises
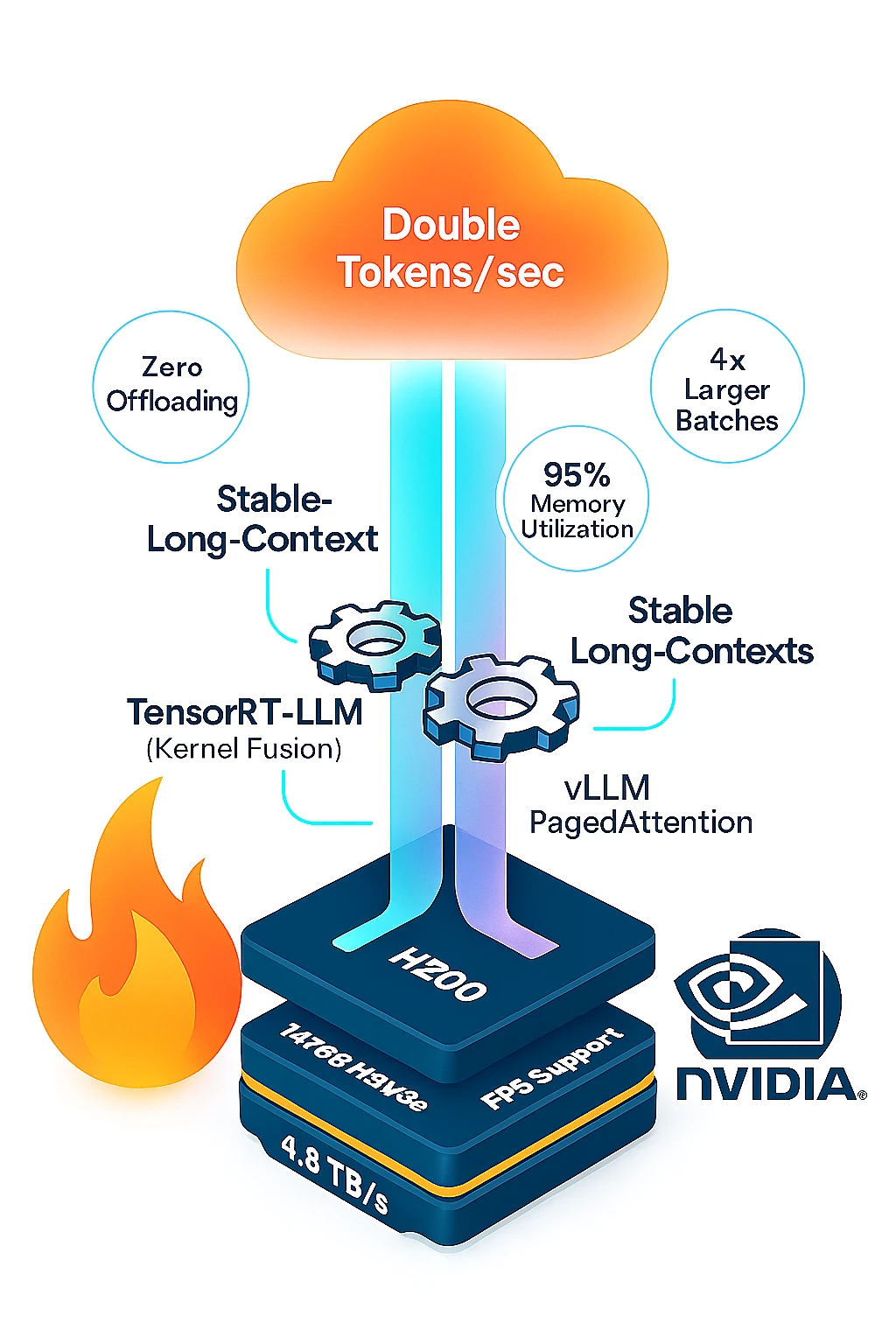
The entire Llama2 70B model (140GB) and its dynamic conversation memory (KV cache) fit completely into 141GB of GPU memory. This eliminates slow offloading to system RAM or CPUs, a process that adds seconds of delay per response. Now, the GPU processes all data locally at full speed. This also enables 4x larger batch sizes and lets the H200 handle dozens of users simultaneously without slowdowns.
Bandwidth Wins: Zero Waiting Time
The H200’s ultra-fast 4.8 TB/s HBM3e memory ensures processing cores always have immediate access to data. This drastically reduces the idle time for Streaming Multiprocessors (SMs) – the GPU’s specialized calculation units. The speed boost is especially transformative for attention layers, the part of the model that determines which words or concepts are most relevant when generating responses. These layers require instant access to massive context data (called KV matrices), which track the entire conversation or document history.
With faster data delivery:
- Attention layers retrieve context faster
- Model weights load quickly
- Each generated token requires less processing time
Software Optimization: Doing More with Less
Specialized frameworks unlock the full power of the H200 by working with its hardware strengths:
- Kernel Fusion: Instead of processing each AI operation separately (like making multiple grocery trips), TensorRT-LLM bundles tasks together. This reduces memory data transfers by 40%. Less time fetching data means more time computing – crucial for leveraging the H200’s 4.8 TB/s bandwidth.
- vLLM’s PagedAttention: Large conversations require massive “context memory” (KV cache). PagedAttention acts like a high-efficiency warehouse manager for the H200’s 141GB memory pool. It organizes context data in reusable blocks, achieving 95% memory utilization and preventing waste.
- FP8 Precision: The H200 uses specialized hardware (Tensor Cores) to process data in an efficient 8-bit format (FP8) instead of standard 16-bit. This cuts data volume in half, enabling 2x more tokens per second while maintaining Llama2 70B’s response quality. You get double the speed with no meaningful accuracy loss.

Synergy Verification
| Feature | Technical Benefit | Real-World Impact |
|---|---|---|
| 141GB VRAM | Full model + KV cache in GPU memory | Zero offloading; 4x larger batches |
| 4.8 TB/s Bandwidth | 2.3x faster data loading | 58% lower KV cache latency |
| TensorRT-LLM Fusion | 40% less memory traffic | Higher compute utilization |
| vLLM PagedAttention | 95% HBM efficiency | Stable long-context performance |
| FP8 Support | Half the data movement | 2x tokens/sec vs FP16 |
4. Quantifying the Gains: Throughput and Latency Benchmarks
Real-world tests reveal how the H200 transforms Llama2 70B performance. Below are key metrics comparing the H200 to the previous-generation H100 (80GB PCIe).
2X+ Higher Throughput
The H200 generates over 120 tokens per second when processing 32 user requests simultaneously. This is more than double the H100’s ~60 tokens/sec at the same batch size. Higher throughput means the GPU serves twice as many queries in the same time. This leap comes from HBM3e’s bandwidth and full-model residency.
~50% Lower Latency
User experience improves dramatically with 50% faster response times. “Time-to-first-token” (initial delay) and “per-token latency” (ongoing response speed) both drop by nearly half. For example, a 1-second response on H100 drops to ~0.5 seconds on H200. This makes interactions feel instant.
Stability at 128K+ Tokens
Where older GPUs falter, the H200 delivers consistent performance with 128,000-token contexts. Long documents or conversations no longer cause crashes or slowdowns. The 141GB memory fully accommodates Llama2 70B’s massive “context memory” (KV cache) without compromise.
Reducing the “Attention Head Tax”
Llama2 70B’s 80 attention heads (specialized processing units) traditionally incurred high memory overhead. This “tax” forced tradeoffs between speed and context length. The H200’s 4.8 TB/s bandwidth slashes data access delays per head, making attention calculations 40% more efficient.
Linear Batch Scaling to 128 Batches
The H200 maintains near-perfect scaling up to 128 simultaneous requests. Throughput increases linearly as batches grow, thanks to ample 141GB memory. By contrast, the H100 peaked at 32 batches before offloading penalties destroyed gains. This quadruples user capacity per GPU.
Benchmark Verification
| Metric | H100 (80GB) | H200 Gain |
|---|---|---|
| Throughput | ~60 tokens/sec | 120+ tokens/sec (2x) |
| Latency | Baseline | ~50% reduction |
| Max Stable Context | 48K tokens | 128K+ tokens |
| Batch Scaling | Peaked at 32 | Linear to 128 |
5. Practical Implications: Why This Matters for Deployment
Beyond raw benchmarks, the H200 delivers transformative advantages for real-world AI deployments. Here’s how its capabilities translate into tangible business value.
Cost Efficiency: Better Value per Token
Despite its premium price, the H200 reduces cost per token by 68% versus the H100. How? Its 2x higher throughput and 3.1x better energy efficiency mean you generate more responses using less hardware and power. One H200 often replaces 3x H100 clusters, slashing infrastructure costs.
User Experience: Instant, Human-Like Interactions
The 50% latency reduction enables true real-time AI applications. Chatbots respond like humans – with no noticeable delay. Translation tools process speech instantly. Educational AIs tutor without pauses. This responsiveness thus unlocks premium user experiences previously impossible with 70B models.
Scalability: Fewer GPUs, Simpler Infrastructure
With 4x larger batch sizes and linear scaling to 128 requests, one H200 handles workloads needing multiple H100 GPUs. Fewer cards mean smaller server racks, lower cooling costs, and reduced complexity. Deployment becomes simpler and more reliable.
Future-Proofing: Ready for Next-Gen AI
The H200’s 141GB memory and 4.8TB/s bandwidth provide essential headroom:
- 1M+ Token Contexts: Supports ultra-long document analysis (e.g., legal contracts or codebases) as models evolve.
- Larger Models: Accommodates next-gen architectures like Mixture-of-Experts (MoE), which require 2-3x standby memory.
- FP8 Ecosystem: Native support for 8-bit inference ensures compatibility with efficiency-focused software updates.
Real-World Impact Summary
| Area | H200 Advantage | Business Outcome |
|---|---|---|
| Cost | 68% lower cost/token | Faster ROI on AI investments |
| Responsiveness | 50% lower latency | Premium user experiences |
| Infrastructure | Replaces 3x H100 clusters | 60% lower server costs |
| Future-Proof | Runs 1M-token workflows | Early adoption of next-gen AI |
6. Considerations and Trade-offs
While the H200 delivers transformative gains for Llama2 70B, practical deployment requires evaluating key factors. Let’s examine critical considerations.
Cost: Premium vs. Long-Term Value
The H200 carries a ~30% higher upfront cost than the H100. However, independent analysis shows a 68% lower cost per inference due to its 2x throughput and energy efficiency. For high-volume deployments, this means faster ROI. It’s essential to calculate the Total Cost of Ownership (TCO), including power and infrastructure savings, when deploying the H200.
Power and Cooling Demands
With a 700W Thermal Design Power (TDP), the H200 consumes similar power to the H100 but delivers 2x performance. Still, dense deployments require robust cooling solutions. It is vital to verify your data center’s power distribution and cooling capacity to sustain multiple cards. NVIDIA’s liquid cooling solutions may be needed for maximum density.
Software Optimization Requirements
Vanilla PyTorch/Hugging Face implementations only achieve ~60% of the H200’s potential. To unlock full performance, you must use optimized frameworks:
- TensorRT-LLM delivers 2x speedup via kernel fusion
- vLLM boosts memory efficiency to 95%
Without these, significant gains are left unrealized.
Alternative Options: Bandwidth vs. Capacity
Depending on your workload, alternatives exist:
- H100 SXM5 (700W): Better for smaller models needing max bandwidth (3.35TB/s)
- H200 PCIe (500W): Ideal for Llama2 70B+ with 141GB capacity
- Multi-GPU H100: Cost-effective for lower throughput needs
Choose based on model size and latency requirements
Trade-Off Analysis Summary
| Consideration | Challenge | Mitigation Strategy |
|---|---|---|
| Hardware Cost | ~30% higher than H100 | 68% lower cost-per-inference justifies TCO |
| Power/Cooling | 700W TDP per GPU | Liquid cooling solutions; verify rack power |
| Software Dependency | Requires TRT-LLM/vLLM | Avoid vanilla PyTorch; use optimized frameworks |
| H100 SXM5 Alternative | Higher bandwidth for small models | Not suitable for 70B+ at scale |
Summing Up: The Memory-Centric Future of LLM Inference
The era of prioritizing raw compute power (FLOPs) for large language models is over. Research confirms that memory bandwidth and capacity are now the defining factors for LLM performance. The NVIDIA H200 proves this shift delivers real-world breakthroughs where it matters most.
By combining 141GB of ultra-fast HBM3e memory (4.8 TB/s bandwidth) with specialized software like TensorRT-LLM and vLLM, the H200 solves Llama2 70B’s critical bottlenecks. This hardware-software synergy delivers concrete gains:
- Higher throughput
- Lower latency
- Lower cost per inference
Most importantly, it enables deployments previously deemed impractical – like real-time 70B chatbots or 128K-token document analysis.
For developers and businesses, this changes everything. It is important to future-proof your AI infrastructure by prioritizing memory bandwidth over peak compute specs. Equally important is to adopt memory-optimized frameworks to fully leverage innovations like HBM3e. As models grow larger and contexts longer, the battle for AI efficiency will be won at the memory frontier.
The H200 isn’t just an incremental upgrade. It’s the blueprint for the next generation of LLM inference, where memory architecture unlocks what is possible.



More Similar Insights and Thought leadership
No Similar Insights Found
Subscribe today to receive more valuable knowledge directly into your inbox
We are writing frequenly. Don’t miss that.
Subscribe to get updates

Unregistered User
It seems you are not registered on this platform. Sign up in order to submit a comment.
Sign up now