FEATURED STORY OF THE WEEK
Best AI Training Server DGX H200: Redefining Performance for Next-Generation AI Workloads

The global AI race is accelerating, and the infrastructure behind it has become the true measure of leadership. Training models that span billions or even trillions of parameters demand extraordinary computational power, memory bandwidth, and data throughput. The NVIDIA DGX H200 stands out as the best AI training server designed to meet this demand. Built on the Hopper architecture, it delivers exceptional performance through HBM3e memory technology and NVLink 5.0. This combination allows organizations to train large-scale foundation models with greater efficiency and precision.
The DGX H200 represents a shift in how AI infrastructure is built and deployed. Traditional GPU clusters struggle to maintain performance as model complexity grows. By contrast, the DGX H200 provides a unified architecture that sustains throughput across intensive workloads. This blog examines why the DGX H200 is recognized as the best AI training server, how it advances beyond the DGX H100, and how enterprises can gain measurable performance and efficiency improvements through its deployment.
1. What Makes the DGX H200 the Best AI Training Server?
The NVIDIA DGX H200 is designed to deliver consistent performance for enterprise-scale AI training and large language model workloads. It functions as the central computing platform for AI factories and advanced data centers, offering high throughput, memory efficiency, and compute density within a unified system. Every aspect of the DGX H200—from GPU architecture to interconnect and software stack—is engineered to reduce latency, handle massive data movement, and maintain performance consistency across intensive workloads.

Built on NVIDIA Hopper Architecture
The DGX H200 is powered by eight NVIDIA H200 Tensor Core GPUs built on the Hopper architecture. Together, these GPUs deliver up to 1.6 TB of HBM3e memory—approximately 1.4 times greater capacity and 1.8 times higher bandwidth than the H100 GPUs. This high-bandwidth memory allows the system to process large datasets and train models faster while minimizing data transfer delays between memory and GPU cores. The Hopper architecture also supports advanced precision modes, such as FP8, which increase computational efficiency for large-scale AI models without compromising accuracy.
NVLink 5.0 and NVSwitch Integration
A defining strength of the DGX H200 is its NVLink 5.0 and NVSwitch technology. NVLink enables direct, high-speed communication between GPUs, while NVSwitch acts as a central hub that allows all eight GPUs to share memory resources efficiently. Together, they provide 900 GB/s of GPU-to-GPU bandwidth and create a unified 1.1 TB/s memory pool. This architecture allows data to move quickly across GPUs, helping AI models train faster and scale across multiple nodes without bottlenecks that often occur in traditional interconnects.
CPU Upgrade and System Design
The DGX H200 includes dual 5th Gen Intel Xeon CPUs to complement its GPU configuration. These CPUs deliver improved core counts, higher memory bandwidth, and better I/O performance. This ensures balanced throughput between computation and data transfer layers, a crucial factor when handling simultaneous AI training, inference, and data preprocessing tasks. The system’s architecture is engineered for thermal stability and consistent performance under high compute loads, making it suitable for continuous AI training operations in enterprise environments.
AI Software Stack Integration
The DGX H200 is preconfigured with the NVIDIA AI software stack, which includes NVIDIA AI Enterprise, Base Command, and communication libraries such as NCCL and NVLink APIs. These tools simplify system management, accelerate model deployment, and provide direct access to performance tuning utilities. For IT and AI teams, this means faster setup, lower maintenance effort, and consistent performance across workloads such as model training, fine-tuning, and inference. The unified software environment also supports frameworks like PyTorch, TensorFlow, and JAX, ensuring broad compatibility with modern AI workflows.
2. DGX H200 vs. DGX H100: A Generational Performance Jump
The DGX H200 represents a measurable leap in AI system performance, memory capacity, and efficiency compared to the DGX H100. Both servers are built on NVIDIA’s Hopper architecture, but the DGX H200 introduces enhancements in GPU memory, bandwidth, and total system design that significantly improve performance in AI training environments. These improvements allow enterprises to handle larger datasets, train more complex foundation models, and reduce total training time for high-parameter workloads.

GPU Memory and Bandwidth
The most notable advancement in the DGX H200 is the transition to HBM3e memory. Each NVIDIA H200 GPU provides 141 GB of high-bandwidth memory—up from 80 GB in the H100—resulting in 1.6 TB total memory across the system. This represents a 76% increase in capacity and a 43% rise in memory bandwidth, reaching 4.8 TB/s. For AI workloads that depend on high data throughput, such as generative AI or large language model training, this improvement directly translates to faster convergence times and more stable training performance under heavy computational loads.
NVLink and NVSwitch Efficiency
Both systems feature NVIDIA NVLink technology with 900 GB/s of inter-GPU bandwidth. However, the DGX H200 enhances efficiency by combining NVLink 5.0 with NVSwitch to create a unified memory pool of 1.1 TB/s bandwidth across eight GPUs. This setup ensures that data moves seamlessly between GPUs without latency spikes, allowing models to operate as if trained on a single large GPU. The result is improved multi-GPU communication efficiency, critical for workloads that require synchronized computation across multiple processors.
System Memory and Computational Balance
Beyond GPU memory, the DGX H200 offers 1.6 TB of total system memory, up from 640 GB in the DGX H100. This increase provides more headroom for data preprocessing, model staging, and concurrent task execution—essential in complex AI pipelines where memory constraints often limit throughput. Although both systems deliver 32 PFLOPS of peak FP8 performance, the DGX H200 sustains this output for longer durations thanks to its improved thermal and power management design. The combination of higher memory capacity, faster bandwidth, and enhanced thermal stability enables consistent, high-performance AI training across diverse workloads.
| Feature | DGX H100 | DGX H200 | Performance Gain |
|---|---|---|---|
| GPU Model | NVIDIA H100 | NVIDIA H200 | – |
| GPU Memory | 80 GB HBM3 | 141 GB HBM3e | +76% Capacity |
| Memory Bandwidth | 3.35 TB/s | 4.8 TB/s | +43% Bandwidth |
| NVLink Bandwidth | 900 GB/s | 900 GB/s (with NVSwitch) | Equal, more efficient |
| Total System Memory | 640 GB | 1.6 TB | +150% Increase |
| Peak FP8 Performance | 32 PFLOPS | 32 PFLOPS | Equal, sustained longer |
3. Real-World Applications: AI Training Without Compromise
The DGX H200 is built to handle the most demanding workloads in artificial intelligence and high-performance computing. Its combination of GPU memory, NVLink interconnect, and system-level efficiency allows organizations to train, simulate, and deploy AI models without performance bottlenecks. This capability extends beyond research labs—enterprises across industries now use the DGX H200 to accelerate decision-making, automate processes, and uncover new insights from massive datasets.
Generative AI and LLM Training
Generative AI and large language models require sustained performance, high memory bandwidth, and low latency across GPUs. The DGX H200 is designed specifically for these needs. Its unified memory pool allows models with trillions of parameters to train faster and more efficiently than on previous-generation systems. With support for FP8 precision and NVIDIA’s NVLink 5.0, organizations can reduce training cycles while maintaining accuracy.
Digital Twin Simulations
The DGX H200 plays a key role in powering digital twin simulations through NVIDIA Omniverse. These simulations replicate real-world systems—such as factories, energy grids, or autonomous vehicle environments—to test and improve operations. The H200’s memory bandwidth and interconnect efficiency allow real-time synchronization of large datasets and 3D visualizations. For industrial use cases, this means faster simulation updates, improved predictive accuracy, and reduced downtime during system testing or optimization.
Enterprise AI Development
Enterprises use the DGX H200 to streamline AI development across departments. The system comes preloaded with NVIDIA Base Command software, which manages workload scheduling, resource allocation, and monitoring across GPU clusters. This simplifies training operations and helps IT teams maintain performance consistency across multiple projects. When paired with NVIDIA AI Enterprise, the DGX H200 becomes a unified platform for developing and deploying AI applications across different domains—whether for model training, fine-tuning, or inference.
Use Case Table: DGX H200 Enterprise Scenarios
| Industry | Application | Benefit |
|---|---|---|
| Energy | Seismic data modeling | Accelerates deep learning interpretation |
| Finance | Fraud detection models | Improves batch processing with faster training cycles |
| Healthcare | Genomic sequencing | Handles large datasets in reduced training windows |
| Manufacturing | Predictive maintenance | Enables real-time analytics through parallel inference |
4. Why Enterprises Are Adopting DGX H200 for AI Factories
Enterprises developing large-scale AI infrastructure increasingly view the DGX H200 as the foundation for their data and model training environments. Its architecture is designed to meet the compute demands of AI factories—facilities that manage the full lifecycle of AI workloads from data preparation to deployment.
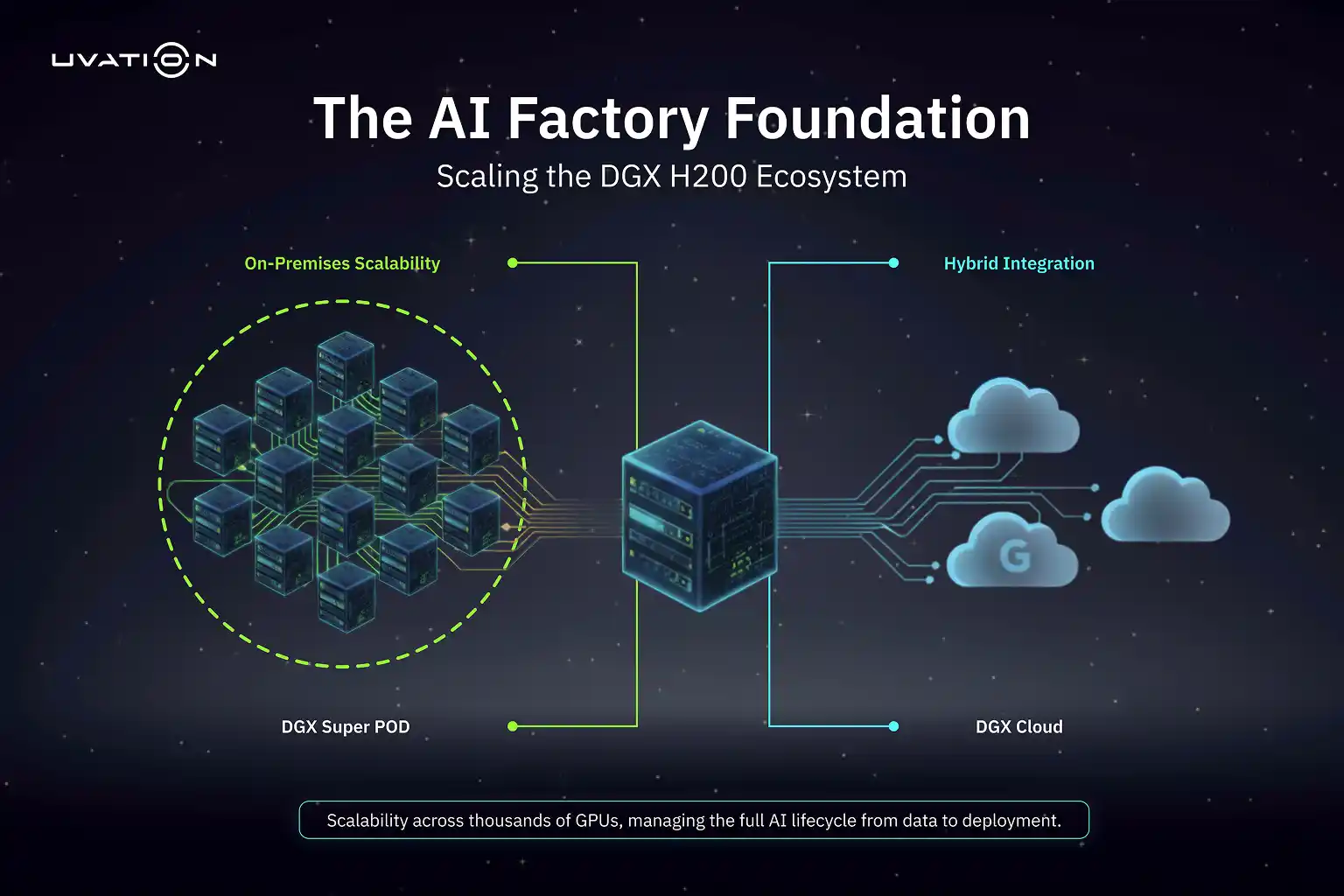
Scalability
The DGX H200 can be deployed individually or as part of NVIDIA’s DGX SuperPOD architecture, enabling organizations to build clusters that operate at exascale performance levels. Each SuperPOD combines multiple DGX H200 systems connected through high-bandwidth NVLink and InfiniBand networking, allowing workloads to scale across thousands of GPUs. This design ensures consistent throughput across distributed AI training tasks, which is essential for organizations building foundation models or multimodal generative AI systems that require significant computational capacity.
Energy Efficiency
Efficiency is a key design factor in modern AI infrastructure. The DGX H200 uses HBM3e memory, which consumes less power per bit transferred compared to earlier generations. This results in lower overall energy usage while maintaining higher memory throughput. Reduced power consumption also decreases cooling requirements, helping data centers manage operational costs more effectively. For enterprises running continuous training workloads, these savings can scale significantly across large clusters.
Operational Simplification
Managing large AI infrastructure requires a coordinated software environment. The DGX H200 simplifies this process through NVIDIA Base Command and AI Enterprise, which together handle workload orchestration, monitoring, and resource scheduling. Base Command provides administrators with centralized visibility into GPU utilization and training progress, while AI Enterprise ensures compatibility with popular AI frameworks. This structured software layer reduces setup time and ongoing maintenance, allowing IT teams to focus on performance tuning and deployment efficiency.
TCO Optimization
A major advantage of the DGX H200 lies in its total cost of ownership (TCO). Because of its larger memory capacity and higher bandwidth, each node can handle larger models that previously required multiple systems. This means fewer servers are needed for the same workload compared to DGX H100 clusters. Organizations using DGX H200 clusters achieve significant improvement in training efficiency and reduced energy per floating-point operation (FLOP). These combined benefits result in lower hardware, power, and maintenance costs across the AI infrastructure lifecycle.
5. Integration with the NVIDIA DGX Ecosystem
The DGX H200 is designed to operate as part of NVIDIA’s broader DGX platform, which brings together hardware, software, and services to create a unified AI computing environment. This structure allows enterprises to manage on-premises and cloud-based AI workloads with consistency, security, and operational efficiency.
Hybrid AI Infrastructure with DGX Cloud
The DGX H200 aligns naturally with DGX Cloud—NVIDIA’s managed cloud platform that provides access to DGX-class computing through leading service providers such as Microsoft Azure, Google Cloud, and Oracle Cloud Infrastructure. Organizations can combine on-premises DGX H200 clusters with DGX Cloud instances, creating a unified training and inference environment. This hybrid setup helps teams move workloads between private data centers and cloud resources without retraining or code modification. It supports rapid experimentation and scaling for AI workloads, particularly when project timelines demand additional computing capacity.
Interoperability through NVLink Switch System
The DGX H200 uses NVIDIA’s NVLink Switch System to connect multiple DGX units into a high-bandwidth computing fabric. NVLink provides direct GPU-to-GPU communication at 900 GB/s per link, while NVSwitch extends that capability across nodes in a cluster. This enables model parallelism—where large AI models are divided across GPUs for faster training—and maintains consistent memory access across all devices. For enterprises developing foundation models, this architecture ensures predictable performance across multi-node training environments.
Unified Software Stack and Security Management
The DGX H200 is delivered with NVIDIA AI Enterprise and Base Command software, forming a consistent operating layer across the DGX platform. AI Enterprise includes optimized frameworks such as TensorFlow, PyTorch, and RAPIDS, validated to run efficiently on DGX systems. Base Command provides an administrative console for job scheduling, monitoring, and data management. Together, they allow teams to deploy and manage large AI models with uniform performance and security standards. Role-based access controls and data isolation features within this software layer also support compliance needs in regulated industries.
Conclusion: The Best AI Training Server for the AI Frontier
The NVIDIA DGX H200 establishes a new benchmark for AI training infrastructure. Its combination of HBM3e memory, NVLink 5.0 interconnect, and unified system design delivers exceptional performance for training large-scale AI models. With up to 141 GB of GPU memory per H200 GPU and 4.8 TB/s bandwidth, it handles massive datasets efficiently and sustains high utilization for prolonged workloads. For enterprises pushing the boundaries of AI, the DGX H200 provides the computational depth and reliability required to train models at an unprecedented scale.
For organizations preparing their next phase of AI infrastructure, the DGX H200 represents a strategic investment in performance and long-term efficiency. Its balance of compute density, memory capacity, and system efficiency positions it as the best AI training server for enterprise-scale deployments. Semifly helps enterprises deploy NVIDIA DGX H200 servers to create high-performance AI environments—delivering the power needed to accelerate model development and stay ahead in the AI frontier.



More Similar Insights and Thought leadership
No Similar Insights Found
Subscribe today to receive more valuable knowledge directly into your inbox
We are writing frequenly. Don’t miss that.
Subscribe to get updates

Unregistered User
It seems you are not registered on this platform. Sign up in order to submit a comment.
Sign up now