FEATURED STORY OF THE WEEK
H100 and Open-Source LLMs: Unprecedented Performance for World-Class Innovation

Unprecedented Performance for World-Class Innovation
In a world where artificial intelligence (AI) is no longer just a tool but a driving force behind innovation, the NVIDIA H100 Tensor Core GPU emerges as the cornerstone of this transformation. Gone are the days when cutting-edge AI advancements were limited to only the big players. The H100 is not just a GPU; it’s the enabler of a revolution in open-source AI, empowering anyone with the ambition and drive to bring their ideas to life at a scale never before imagined.
This isn’t just about pushing boundaries. It’s about tearing them down. From enhancing the capabilities of open-source large language models (LLMs) like ChatGPT, Llama, DeepSeek, and Falcon, the H100 redefines what’s possible. Built on the groundbreaking Hopper architecture, this GPU is engineered for those ready to leave the status quo behind and embrace the future of AI—where performance meets affordability and scalability meets accessibility.
For developers and researchers pushing the limits of AI, the H100 doesn’t just change the game. It redefines it.
Ready to unlock the power of AI with the H100? It’s time to turbocharge your LLM projects like never before.
Powering the Open-Source AI Revolution
The NVIDIA H100 isn’t just a hardware upgrade. It’s the launchpad for the next era of AI—a revolution that breaks down the barriers to powerful, scalable, and accessible AI for developers everywhere. With its foundation in the revolutionary NVIDIA Hopper architecture, the H100 redefines what’s possible for open-source large language models (LLMs). It’s about taking the best of what AI has to offer and giving it to the people who drive innovation—fast, open, and boundless.
Dominate the LLM Frontier with the Transformer Engine
Step into the world of LLMs powered by the Transformer Engine—an innovation built to handle trillion-parameter models with ease. With the H100, developers can now accelerate open-source LLM models like DeepSeek, Llama, BLOOM, and Falcon at an unprecedented pace—cutting training times by up to 30 times compared to older GPUs. Imagine turning what used to take months into mere days, while slashing both the cost and complexity of scaling generative AI models.
For teams working in open-source ecosystems, this power means progress without limits. Whether you’re refining a multilingual chatbot, crafting ethical AI frameworks, or innovating in collaborative research, the H100 ensures you never hit a computational bottleneck. Instead of waiting on hardware to catch up, you’re in the driver’s seat, creating and experimenting at the pace of imagination.
The H100 doesn’t just power LLMs. It turbocharges them, unlocking a whole new world of possibilities in open-source AI.
Ready to turbocharge your LLMs? Try the power of H100 GPUs today!
Transformative Technologies Inside the H100 GPU
The NVIDIA H100 is more than just a GPU. It’s a transformative powerhouse that redefines what’s possible in the world of AI and large language models. Let’s take a deeper dive into the cutting-edge technologies that power the H100 and make it the ultimate tool for open-source AI innovation.
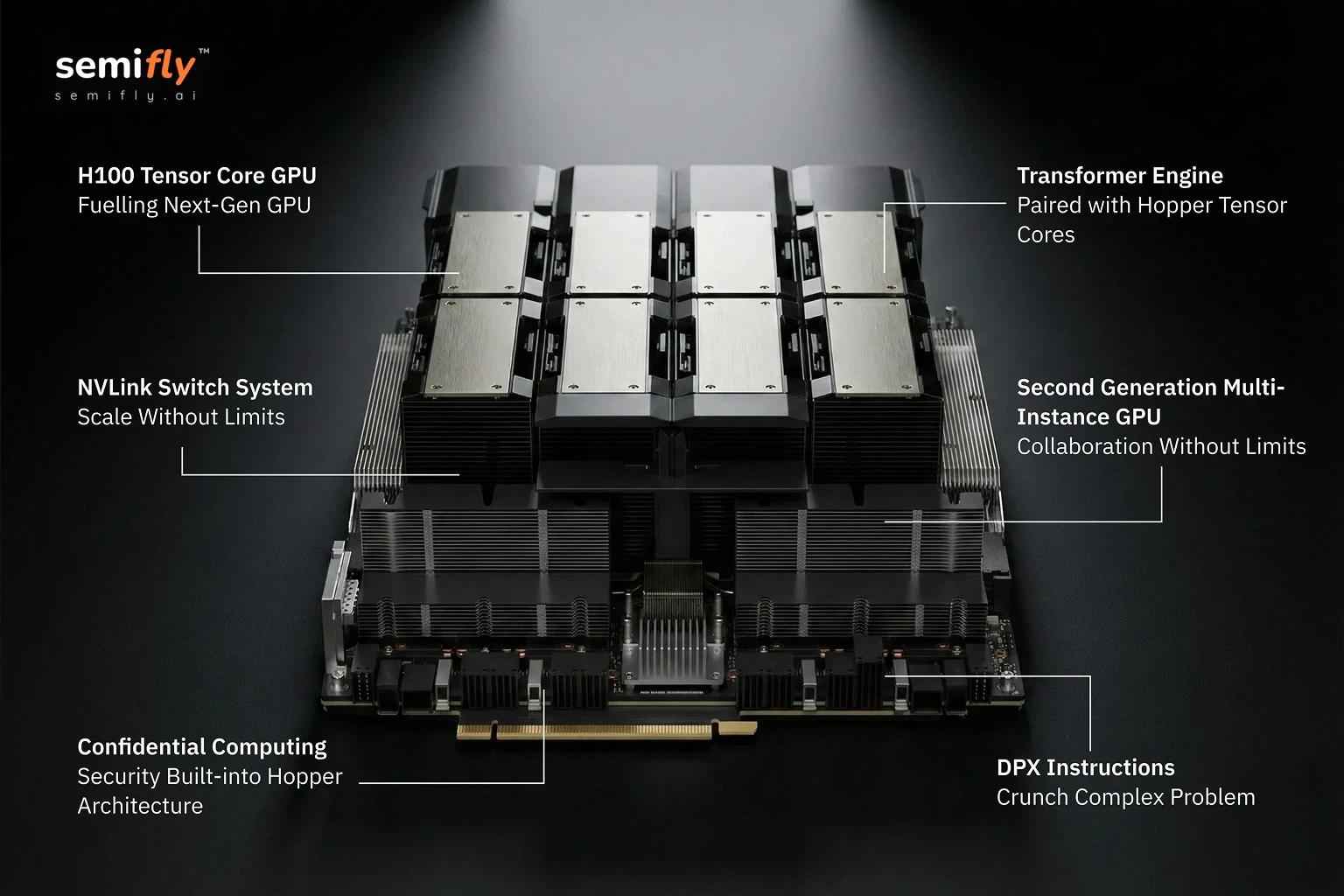
H100 Tensor Core GPU: Fueling Next-Gen Language Models
At the heart of the H100 lies its Tensor Core GPU, engineered with 80 billion transistors using TSMC’s 4N process. This state-of-the-art design powers next-gen language models, driving efficiency and scalability for teams working on complex billion-parameter architectures. It’s built for those who need more than just raw computational power—it’s built for those pushing the boundaries of what AI can do.
With the H100, open-source developers can scale their models like never before, accelerating training times and increasing the efficiency of the entire process. Whether you’re working on cutting-edge research or building the next big AI app, this GPU is designed to get you to the finish line faster and cheaper than anything before it.
Transformer Engine: The AI Powerhouse
If you thought the Tensor Core GPU was powerful, meet the Transformer Engine. This next-level AI powerhouse pairs Hopper Tensor Cores with advanced software to boost AI training and model performance. Tailored specifically for transformer models, the Transformer Engine dynamically adjusts between FP8 and FP16 precision, providing a 30x performance increase in open-source LLM-based generative AI, language tasks, and trillion-parameter architectures.
It’s a game-changer for teams working on complex models, enabling them to train faster and more efficiently—whether they’re building cutting-edge chatbots, fine-tuning for multilingual capabilities, or enhancing generative AI.
NVLink Switch System: Scale Without Limits
Where scalability meets speed: The NVLink Switch System allows seamless multi-GPU scaling across servers, delivering 9x higher bandwidth than previous InfiniBand solutions. For teams training large, complex LLMs, this is scalability reimagined. No more bottlenecks. Just high-speed, frictionless scaling that lets you train at an enterprise level without sacrificing speed or performance.
This system opens up new possibilities, enabling teams to scale their models without hitting limits. From startups to global enterprises, NVLink ensures that your AI infrastructure can grow as fast as your ideas.

Confidential Computing: Security Built-In
In a world where data privacy and security are paramount, the NVIDIA H100 is the first GPU to integrate confidential computing directly into its architecture. It secures sensitive training data and user interactions in real-time—without compromising performance. Whether you’re working with healthcare records, financial data, or proprietary research, the H100 ensures your data stays protected even during training.
This is more than just security—it’s peace of mind. With the H100, teams can collaborate on AI innovation without worrying about breaches or data leaks, all while complying with rigorous privacy standards like HIPAA and GDPR.
Second-Generation Multi-Instance GPU (MIG): Collaborate Without Limits
The H100’s second-generation MIG technology takes collaboration to the next level. By partitioning the GPU into multiple, isolated units, it allows for secure, parallel model training and inference. This means you can now run multiple open-source LLM models concurrently, supporting up to 7x more contributors without sacrificing performance.
For open-source teams, this means greater efficiency, faster iteration, and more people working on a single project simultaneously. Whether you’re a startup, university, or research institution, the H100’s MIG technology ensures your team has all the resources it needs to innovate without limitations.
DPX Instructions: Crunch Complex Problems
The H100’s DPX instructions are designed to accelerate dynamic programming tasks—by up to 40x compared to traditional CPUs. This makes complex operations like attention mechanism optimization, multilingual token processing, and graph-based model fine-tuning faster and more efficient. With DPX, what used to take hours now takes minutes, dramatically speeding up the development process for even the most challenging AI tasks.
This breakthrough in speed allows teams to iterate faster, explore more complex models, and solve problems that were previously too time-consuming to tackle. With the H100, complex AI challenges become opportunities for rapid innovation.
Maximize Your LLM Investment: How the H100 Pays Dividends for Years
The NVIDIA H100 isn’t just a short-term investment in computational power; it’s an enduring catalyst that drives long-term success for open-source AI and LLM development. From democratizing cutting-edge innovation to enabling seamless collaboration and scaling, the H100 pays dividends for years to come.
Democratize Cutting-Edge LLM Development
The true power of the H100 lies in its ability to break down the traditional barriers to innovation. Training massive LLMs like LLaMA and Falcon is now 30x faster, turning what was once a months-long process into a matter of days. By dramatically reducing training times and slashing cloud costs by up to 90%, the H100 makes it possible for researchers, startups, and nonprofits to experiment, develop, and iterate freely—without breaking the bank.
For teams focused on improving ethical AI, eliminating bias, or aligning models with societal values, the H100 accelerates iteration cycles, enabling faster refinement of models. Imagine grassroots developers working on AI for local languages, medical diagnostics, or other community-driven solutions—all without the prohibitive costs that once stood in their way.
Unlock Collaborative Efficiency
Imagine transforming your H100 GPU into seven independent innovation hubs. That’s what Multi-Instance GPU (MIG) technology offers. By running multiple experiments in parallel—whether it’s fine-tuning models, testing datasets, or optimizing inference—MIG allows teams to collaborate efficiently and effectively, without competing for resources.
Data scientists, developers, and researchers can now work in parallel, speeding up the pace of innovation and eliminating waiting times. For startups, this means being able to prototype faster; for universities, it means hosting scalable hackathons; and for enterprises, it means testing multiple AI solutions simultaneously. The days of wasting time on resource constraints are over—now it’s all about seamless, uninterrupted progress.
Scale Open-Source Ambition
The H100 GPU is designed to handle big data—and by “big,” we mean massive. With 3TB/s memory bandwidth, the H100 can handle trillion-token multilingual datasets with ease, unlocking AI potential for over 500 global languages—even those with limited digital footprints. This unprecedented scalability allows teams to work on rare dialects, preserve endangered languages, or even create educational tools for underserved regions—all at the enterprise scale.
By empowering open-source projects to handle vast datasets, the H100 enables a level of ambition previously only achievable by tech giants. Now, smaller teams and community-driven initiatives can think and act like Fortune 500 companies, all while staying true to their open-source ethos.
Build Trust in Community Models
Trust is the foundation of every great community project. With the H100’s built-in confidential computing, open-source teams can now work with sensitive data without worrying about breaches. Whether it’s medical records, indigenous dialects, or proprietary research, the H100 ensures that every byte of data is protected, even during training.
This isn’t just about security—it’s about building trust from the ground up. With the H100, open-source teams can collaborate on complex and ethically sensitive AI projects—like diagnosing rare diseases or preserving marginalized languages—without fearing data leaks or non-compliance. This level of trust isn’t just a luxury; it’s a necessity for responsible AI development.
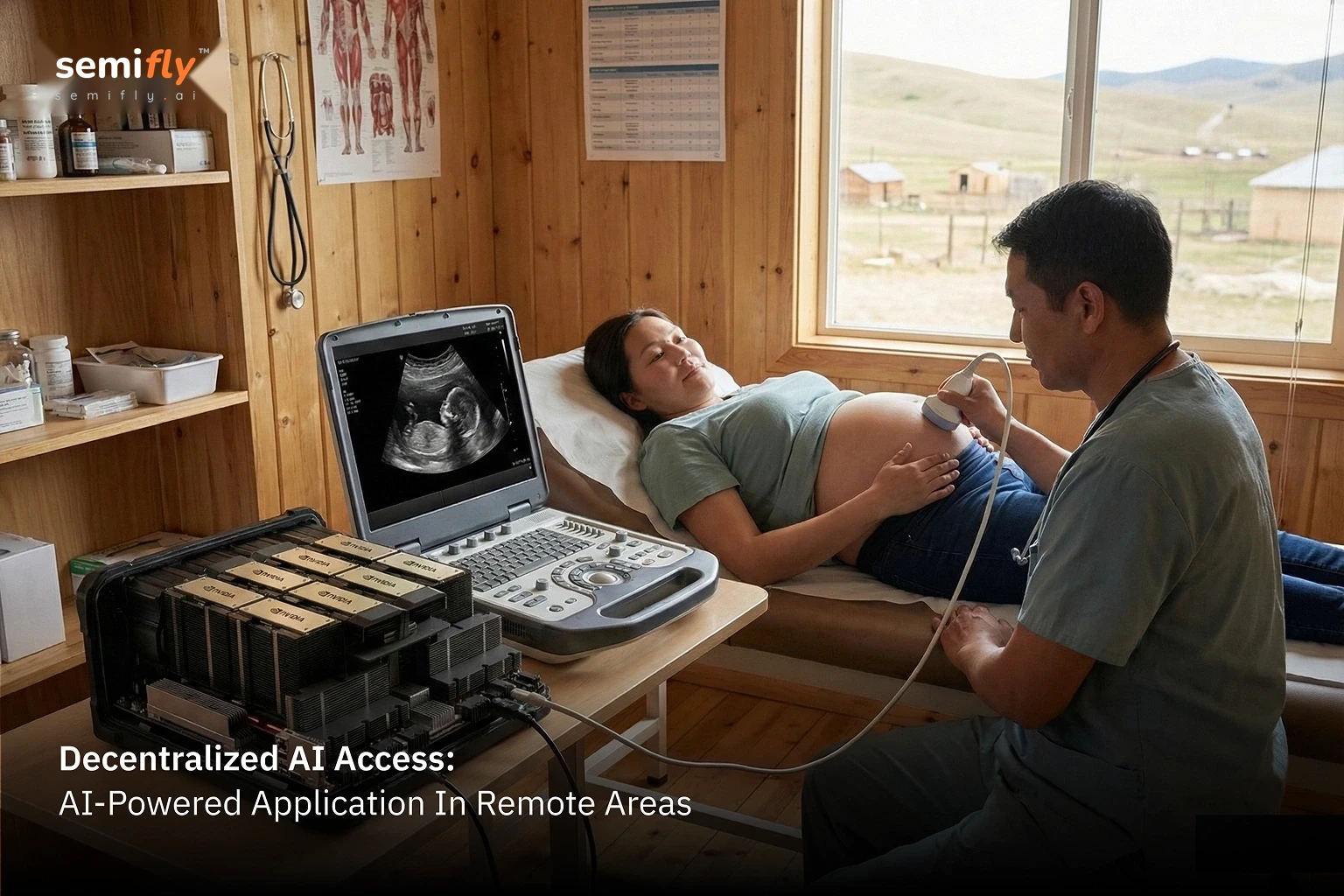
Decentralize AI Access
The H100 doesn’t just power AI in traditional data centers. It shrinks entire data centers into pocket-sized powerhouses, bringing AI to places it’s never been before. Imagine rural classrooms running real-time language tutors, remote clinics diagnosing with AI-powered ultrasound, or farmers analyzing crop health on their smartphones. No cloud? No problem.
By cutting reliance on expensive infrastructure, the H100 ensures that AI can reach even the most remote corners of the globe. Transformative technology no longer has to be confined to large cities or wealthy regions—it’s now available wherever innovation is needed most.
Future-Proof Open Ecosystems
The H100 isn’t just a GPU for today—it’s built for tomorrow. Thanks to its Hopper architecture, the H100 is fully compatible with open-source frameworks like Hugging Face and PyTorch, ensuring that your models stay ahead of the curve. You can build, scale, and adapt without being locked into proprietary ecosystems.
With the H100, you’re not just future-proofing your AI infrastructure; you’re creating an open environment that evolves alongside the community. Collaborate globally, adapt to new tools at the drop of a hat, and scale your models as fast as the AI frontier itself. The future of AI is open—so is the future of the H100.
Ready to Transform “What If?” into “What’s Next?”
The future of AI isn’t some distant dream—it’s unfolding right now. With the NVIDIA H100 Tensor Core GPU, the potential to accelerate open-source LLMs and unlock the true power of artificial intelligence has never been more tangible. From redefining performance benchmarks to making cutting-edge AI more accessible than ever before, the H100 is the catalyst that transforms ideas into reality.
Whether you’re developing ethical AI models, scaling multilingual capabilities, or contributing to the open-source ecosystem, the H100 empowers you to push the boundaries of what’s possible. It’s not just about faster training times or cheaper cloud costs; it’s about making AI more democratic, more accessible, and more impactful for everyone.
So, are you ready to transform your “what ifs” into “what’s next”? With the power of the H100, the possibilities are limitless. Don’t just watch as the AI revolution unfolds—be part of it.
Contact our experts today to discuss which H100 GPU fits your business needs and start building the future of AI today.



More Similar Insights and Thought leadership
No Similar Insights Found
Subscribe today to receive more valuable knowledge directly into your inbox
We are writing frequenly. Don’t miss that.
Subscribe to get updates

Unregistered User
It seems you are not registered on this platform. Sign up in order to submit a comment.
Sign up now