
When enterprises think about deploying AI at scale, the conversation often begins with performance metrics — TFLOPs, bandwidth, memory. But when you’re building for real-world workloads like LLM inference, fine-tuning, or sovereign AI enablement, what you really need is clarity on the architecture that runs under the hood.
That’s why understanding the Nvidia H200 component descriptions isn’t about checking boxes — it’s about evaluating infrastructure fit.
At Semifly, we design AI stacks where the hardware isn’t the centerpiece — the outcome is. And that starts by asking: what does each component enable in your use case?
01Why Component-Level Understanding Matters
Buying the Nvidia H200 isn’t a plug-and-play decision. It affects how you:
- Design inference pipelines
- Optimize memory for context-heavy LLMs
- Manage power and cooling across clusters
- Orchestrate jobs in Foundry or containerized MLOps
The goal is total throughput across the stack — not just high performance on isolated benchmarks.
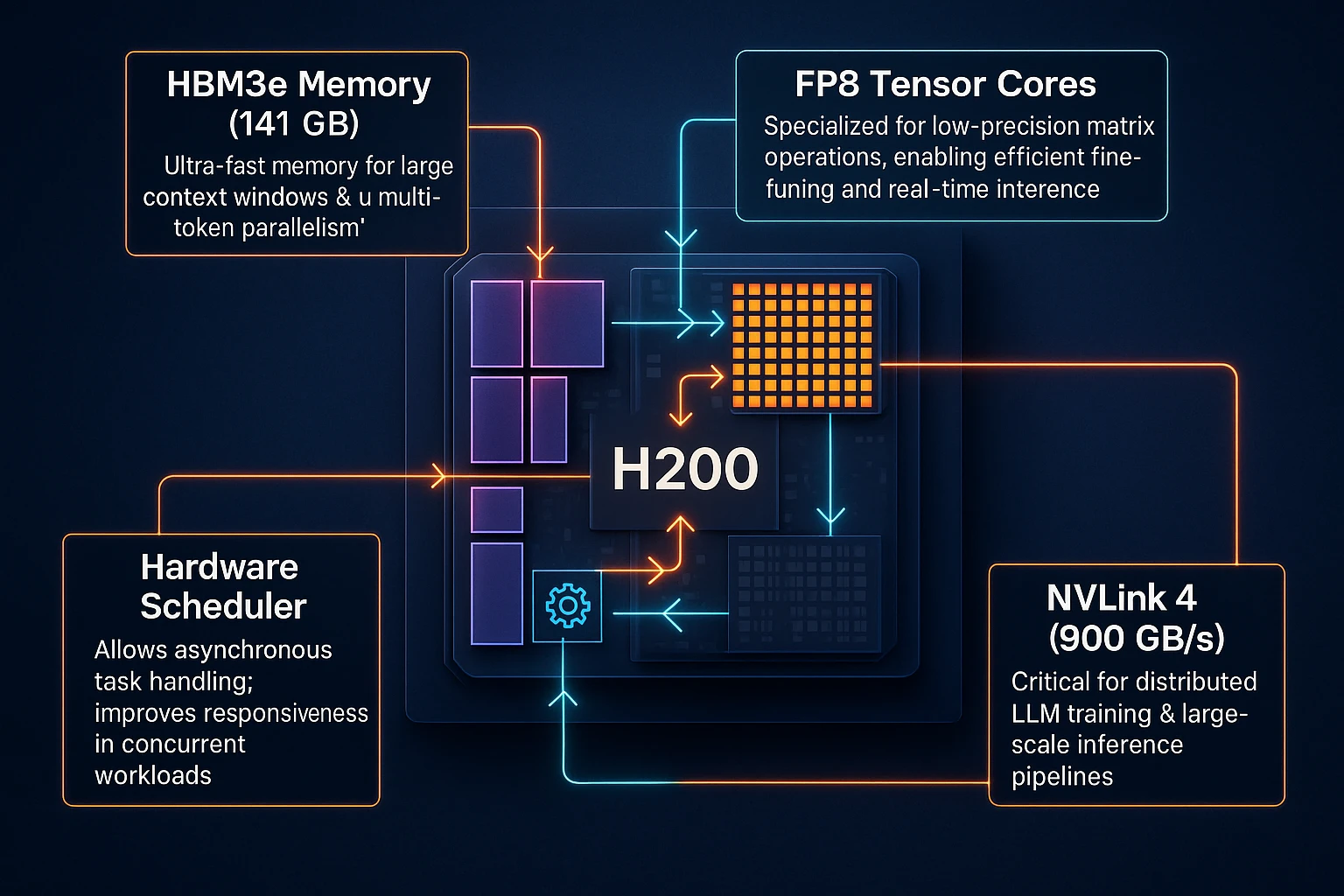
02Breaking Down the H200: What’s Inside and Why It Matters
Let’s zoom into the core components that drive meaningful outcomes:
| Component | What It Does | Why It Matters for LLMs |
|---|---|---|
| HBM3e Memory (141 GB) | Ultra-fast, high-capacity memory integrated on-package | Handles large context windows and multi-token parallelism with low latency |
| FP8 Tensor Cores | Specialized for low-precision matrix operations | Enables efficient fine-tuning and real-time inference of large language models |
| NVLink 4 (900 GB/s) | High-speed GPU-to-GPU interconnect | Critical for distributed LLM training and large-scale inference pipelines |
| Hardware Scheduler | Allows asynchronous task handling on GPU | Improves responsiveness in concurrent workloads and job queuing |
| NVSwitch | Scales GPU communication across baseboards | Enables seamless scaling across 8+ GPU servers like DGX or BasePOD clusters |
| ConnectX-7 (InfiniBand/NIC) | High-throughput networking with 400 Gb/s bandwidth | Provides low-latency communication between nodes in multi-rack training setups |
| PCIe Gen5 Interface | Hosts high-bandwidth peripheral connectivity | Boosts I/O throughput for storage, accelerators, and fast CPUs |
| Baseboard Power Delivery (Up to 700W) | Custom server boards to handle power draw and thermal envelope | Ensures stable performance under sustained AI load conditions |
Beyond the chip itself, Nvidia’s H200 infrastructure relies on NVSwitch, ConnectX-7 NICs, and PCIe Gen5 to deliver reliable throughput across enterprise-scale training and inference. These core components — while invisible in spec sheets — are essential for LLM workloads that span nodes, racks, and clusters.

Semifly’s architecture-first model ensures every H200 deployment is matched to these exact capabilities from day one.
03H200 in the Real World: Where It Fits
This isn’t a one-size-fits-all GPU. The H200 is overkill for lightweight inference, but a game-changer for:
- Enterprises building in-house language models (e.g. finance, legal, telecom)
- Running multi-turn conversations with large context (e.g. 32K+ tokens)
- Performing siloed LLM training where data residency and compliance are critical
- Teams requiring high-efficiency fine-tuning with limited GPU allocation
If you’re still scaling on A100s or even H100s and hitting memory walls or latency cliffs, the H200 can unlock serious gains — but only when paired with the right architecture.
04How Semifly Aligns Your Stack with H200’s Capabilities
We’ve seen what happens when teams buy top-tier GPUs but fail to extract their full value. The reasons are usually:
- Inefficient container orchestration
- Poor interconnect design
- Mismatch between software pipelines and hardware constraints
- Lack of observability for real-time tuning
That’s why we don’t sell parts — we deliver aligned systems.
With Semifly, your H200 deployment comes with:
- Pre-validated GenAI blueprints for Foundry, MGX, or on-prem clusters
- GPU-aware orchestration layers tuned to model behavior, not just memory usage
- Security & compliance hardening for AI in regulated industries
- And most critically — a design approach where performance meets purpose
Whether you’re deploying DGX BasePOD, MGX servers, or PCIe nodes, we factor in not just the GPU — but the NVSwitch fabric, power envelope, and interconnect design behind it.
05Final Take: Don’t Buy the H200 for Specs — Buy It for Fit
You don’t need 141 GB of memory unless your models do.
You don’t need FP8 unless your pipeline can exploit it.
You don’t need NVLink unless your jobs are multi-GPU aware.
But when you do need those things?
The H200 is the best tool in the world.
And Semifly helps you wield it, intelligently.
Thinking about a cluster upgrade?
Schedule a strategic session to map your model requirements to the right infra stack.


