FEATURED STORY OF THE WEEK
NVIDIA H200 and Kubernetes: Unlocking Enterprise AI at Scale

Imagine deploying a high-performance AI cluster—each GPU delivering unprecedented speed, memory, and efficiency—all orchestrated seamlessly through Kubernetes. This is no longer a future aspiration, but a present-day reality made possible by the NVIDIA H200 GPU. The H200 represents a generational leap in high-performance computing and AI acceleration.
While the H200 provides the computational backbone, it is Kubernetes that delivers the orchestration required to fully realize its potential in enterprise environments. Originally designed to manage containerized applications, Kubernetes has evolved into a de facto standard for scaling AI/ML workloads across on-premises and cloud environments. Its ability to dynamically allocate GPU resources, automate scaling, and integrate with advanced scheduling frameworks ensures that H200-powered clusters do not just perform—they adapt.
For technology and business leaders, the intersection of NVIDIA H200 and Kubernetes orchestration represents an inflection point. Together, they enable elastic, enterprise-grade AI infrastructure that can scale on demand, optimize costs, and accelerate time-to-insight.
This blog will serve as a definitive guide for IT leaders, showing how to leverage H200 within Kubernetes environments to drive AI innovation, streamline CI/CD pipelines, and prepare data centers for the next generation of AI workloads.
1. What Makes the NVIDIA H200 a Game-Changer for Kubernetes-Driven AI?
The NVIDIA H200 GPU delivers specifications that address the growing complexity of enterprise AI workloads. It is the first GPU to integrate 141 GB of HBM3e memory, a leap from the H100’s 80 GB HBM3, combined with 4.8 TB/s of memory bandwidth. This means the H200 can handle significantly larger datasets in memory, reducing the need to constantly move data between GPU and system memory, which often creates bottlenecks.
In benchmarked workloads such as inference tasks, the H200 has shown 1.6x to 1.9x performance improvements over the H100. For enterprises running AI/ML pipelines, this translates to faster training times, more responsive inference engines, and better throughput in production environments.
Strategic Impact: Unlocking Larger Models and Faster Workflows
The H200’s expanded memory and bandwidth enable the training of multi-trillion-parameter AI models that were previously impractical without heavy model sharding. Larger context windows for LLMs, advanced simulations in fields like climate modeling, and more accurate digital twins in manufacturing are all made possible by this leap in GPU architecture.
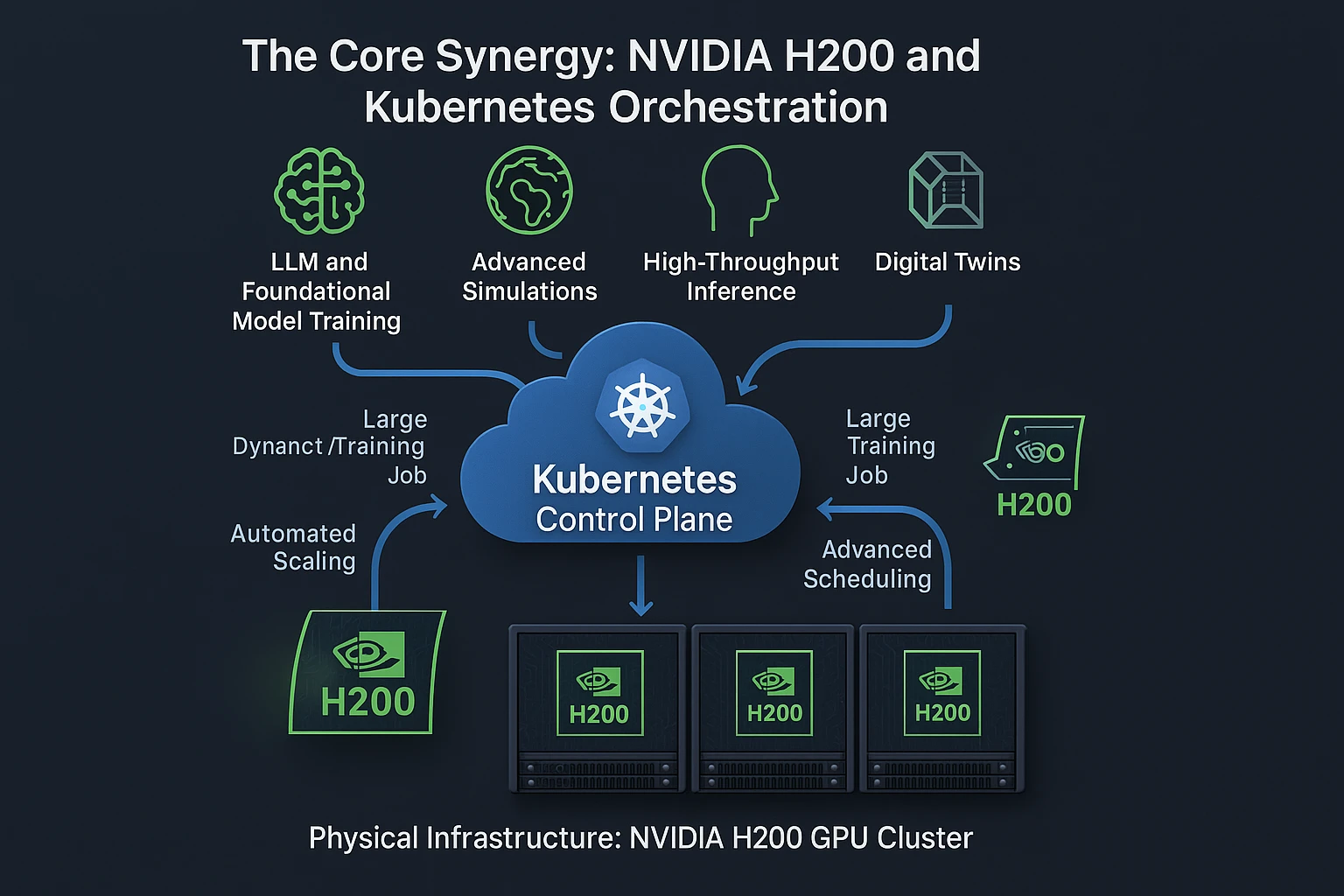
When paired with Kubernetes, these capabilities are amplified. Kubernetes provides dynamic scheduling of GPU resources, automated scaling of workloads, and integration with AI-specific frameworks like Kubeflow. This ensures that organizations can not only run bigger models but also manage them efficiently across clusters. For example, Kubernetes can allocate multiple H200 GPUs to a single pod for model-parallel training while simultaneously distributing inference workloads across nodes for production-scale AI services.
Why It Matters for Enterprises
From a strategic standpoint, the H200 allows enterprises to consolidate infrastructure while increasing performance. Workloads that previously required large-scale multi-GPU clusters can now be executed on fewer, more powerful nodes. Combined with Kubernetes’ ability to orchestrate resources elastically across on-premises and cloud environments, CIOs and CTOs gain the dual advantage of performance efficiency and cost control.
2. How Can Kubernetes Seamlessly Orchestrate H200-Powered GPU Workloads?
Enterprises adopting the NVIDIA H200 GPU need a robust orchestration layer to extract its full value. Kubernetes has become the de facto standard for container orchestration, and its GPU-aware extensions make it a natural fit for managing high-performance workloads. By combining the H200 and Kubernetes, organizations can achieve elastic scaling, efficient resource allocation, and enterprise-grade workload automation.
Foundation: Kubernetes Device Plugin Framework
At the core of GPU orchestration in Kubernetes is the device plugin framework. This framework allows hardware vendors like NVIDIA to expose GPUs as first-class resources inside a Kubernetes cluster. Once installed, Kubernetes can schedule GPU-accelerated workloads just like CPU or memory resources, ensuring containers receive access to the right hardware without manual intervention.
For H200-powered systems, the device plugin ensures workloads can request and utilize advanced GPU features such as massive HBM3e memory or multi-instance GPU (MIG) partitioning. This abstraction layer is critical in enterprise environments where consistency, repeatability, and automation are required at scale.
GPU Operator Stack: Enabling Cluster Readiness
The NVIDIA GPU Operator simplifies the deployment and management of GPU software components on Kubernetes clusters. Instead of requiring IT teams to manually configure drivers or monitoring tools, the operator automates the process and ensures all dependencies remain up to date.

Key components of the GPU Operator stack include:
- NVIDIA GPU Driver: Enables communication between the H200 hardware and the Kubernetes environment.
- NVIDIA Container Toolkit: Provides the necessary tools to integrate NVIDIA GPUs into containerized environments, allowing applications to use GPU resources efficiently.
- NVIDIA Kubernetes Device Plugin: Allows users to run GPU-enabled containers in the Kubernetes cluster, enabling the management of NVIDIA GPUs as resources.
- NVIDIA DCGM (Data Center GPU Manager): Provides health monitoring, telemetry, and diagnostics for GPUs at scale.
- NVIDIA MIG Manager for Kubernetes: Enables partitioning of a single H200 GPU into multiple secure, isolated GPU instances, improving utilization for multi-tenant clusters.
Together, these components form a production-ready stack that allows Kubernetes to run GPU-intensive applications reliably.
Cloud and Enterprise Support for H200
The NVIDIA H200 is supported across leading enterprise Linux and Kubernetes distributions, ensuring broad compatibility. Red Hat OpenShift provides enterprise-grade Kubernetes platforms with built-in GPU operator support, making them well-suited for hybrid cloud deployments.
Public cloud providers have also extended their managed Kubernetes services to include NVIDIA GPUs. Google Kubernetes Engine (GKE) and AWS Elastic Kubernetes Service (EKS) both support GPU scheduling, with ongoing updates to include the latest GPU variants like the H200 (Google Cloud, AWS). This ensures enterprises can deploy H200-powered workloads consistently across on-premises clusters and cloud environments without re-architecting their applications.
By unifying hardware and orchestration through Kubernetes, organizations can operationalize the full capabilities of the NVIDIA H200. From high-memory AI model training to multi-tenant inference services, enterprises gain the flexibility to run diverse workloads with the assurance of automation, observability, and enterprise-grade support.
3. What Kubernetes Patterns Optimize H200 Performance at Scale?
Running NVIDIA H200 GPUs inside Kubernetes clusters requires more than basic orchestration. To maximize performance, enterprises must adopt proven patterns that ensure optimal resource sharing, scheduling, and elasticity. These patterns enable organizations to balance cost efficiency with peak workload performance, whether in training massive AI models or supporting multi-tenant inference environments.
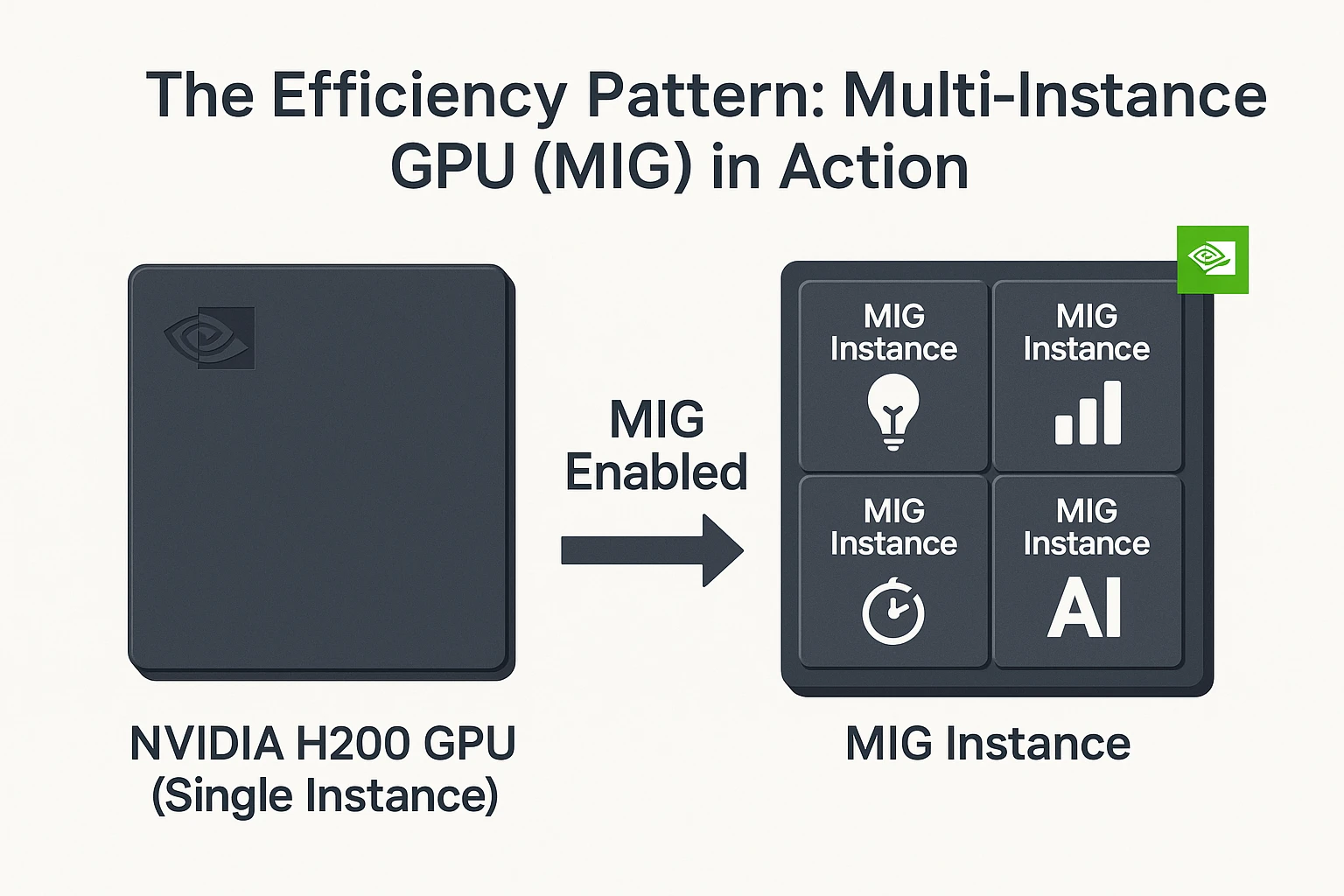
Resource Sharing with Multi-Instance GPU (MIG)
The H200’s Multi-Instance GPU (MIG) capability allows a single physical GPU to be partitioned into several smaller, isolated instances. Each MIG partition behaves like an independent GPU, with its own memory, compute cores, and cache resources.
For Kubernetes environments, MIG provides fine-grained resource allocation. For example, in a multi-tenant cluster, research teams can run smaller inference jobs on separate MIG partitions without interfering with one another. This improves GPU utilization rates and reduces idle capacity. Experts often recommend MIG in shared clusters where multiple workloads—ranging from model training to real-time analytics—must coexist efficiently.
Advanced Scheduling with KAI Scheduler
Beyond basic scheduling, advanced GPU workloads benefit from gang scheduling and co-scheduling. The open-source Kubernetes AI (KAI) Scheduler extends Kubernetes’ default scheduling capabilities to better manage large-scale, interdependent workloads.
Gang scheduling ensures that all required pods of a distributed job start simultaneously, avoiding wasted GPU cycles. Co-scheduling allows workloads with shared dependencies to run together, optimizing data locality and minimizing communication overhead. Workload consolidation further enhances efficiency by tightly packing jobs onto available GPU nodes.
When paired with the H200’s high-bandwidth NVLink interconnects, these scheduling patterns reduce latency and improve throughput for large, distributed AI training tasks, such as multi-trillion parameter models.
Cluster Autoscaling with GPU-Aware Operators
Elastic scaling is critical in modern AI infrastructure. Kubernetes provides Horizontal Pod Autoscaler (HPA) to scale workloads dynamically based on real-time metrics. For GPU clusters, NVIDIA extends this with GPU-aware operators like the NVIDIA NIM Operator, which can adjust GPU resources in response to workload demand.
For example, during a surge in inference requests, autoscaling can spin up additional GPU-backed pods on H200 clusters, ensuring low response times. When demand falls, the system scales down, reducing operational costs. In hybrid cloud deployments, this elasticity helps enterprises strike a balance between performance and budget efficiency.
4. Where Is H200 Already Powering Kubernetes at Hyperscale?
The NVIDIA H200 is not just a roadmap product; it is already in production across hyperscale cloud and managed Kubernetes environments. Early adoption at this scale demonstrates both the maturity of the ecosystem and the enterprise readiness of H200-powered infrastructure. These deployments show how Kubernetes can harness H200 performance at a massive scale without requiring enterprises to reinvent their operating models.
Cloud Deployments: Google Cloud A3 Ultra VMs on GKE
Google Cloud has introduced A3 Ultra VMs on Google Kubernetes Engine (GKE), featuring NVIDIA H200 GPUs. These instances are designed for large-scale AI training and inference workloads and support clusters of up to 65,000 nodes out of the box.
For enterprises, this represents a turnkey path to hyperscale. Instead of building GPU clusters from scratch, organizations can provision H200-powered environments through GKE and take advantage of Google’s native integration with Kubernetes. This ensures predictable performance, automated cluster scaling, and enterprise-grade security controls.
Managed Contexts: CoreWeave’s Kubernetes Service
CoreWeave, a specialized GPU cloud provider, has also optimized its managed Kubernetes service (CKS) for NVIDIA deployments. This service is designed for speed, elasticity, and high-throughput AI workloads, making it particularly relevant for generative AI, rendering, and scientific simulations.
Unlike general-purpose cloud providers, CoreWeave tailors its infrastructure specifically for GPU-intensive applications. Enterprises using CKS benefit from rapid cluster provisioning, workload-aware autoscaling, and deep integration with the NVIDIA GPU Operator stack. All this shows how alternative providers are competing on speed-to-market and adaptability, giving clients greater choice in balancing cost, performance, and vendor strategy.
Summary: Kubernetes Patterns for H200 Workloads
| Pattern | Benefit | Source |
|---|---|---|
| MIG | Flexible GPU slicing, shared workloads | NVIDIA GPU Operator |
| KAI Scheduler | Reduced latency & better GPU utilization | NVIDIA Developer |
| Autoscaling | Dynamic resource management | NIM Operator |
| Managed Clusters | Fast deployment at hyperscale | GKE / CoreWeave |
Conclusion
The NVIDIA H200 GPU represents more than just incremental progress—it signals a structural shift in how enterprises can accelerate AI workloads. With 141 GB of HBM3e memory and unmatched bandwidth, the H200 brings new efficiency to training massive language models, running high-fidelity simulations, and scaling inference at production levels. But hardware alone cannot transform outcomes. The orchestration layer is equally critical, and that is where Kubernetes enters as the backbone of modern AI infrastructure.
By combining H200 and Kubernetes, enterprises gain a platform that is not only high-performing today but resilient to tomorrow’s demands. Workloads that once strained data centers can now be distributed, scheduled, and scaled with far greater efficiency. This alignment ensures infrastructure can adapt to new AI models, fluctuating demand, and multi-cloud strategies—without constant reinvestment or disruptive redesigns.
For IT leaders, the strategic value is clear: adopting H200 and Kubernetes is not just about meeting technical requirements; it is about positioning enterprise infrastructure to be durable, efficient, and cost-justified in the long run. It is a foundation that balances peak performance with enterprise-grade governance, giving clients confidence that their AI capabilities will deliver sustained ROI.
At Semifly, we help enterprises translate these capabilities into business advantage. Our approach goes beyond deploying hardware and software. We evaluate the client’s workloads, compliance requirements, and long-term scaling goals to design Kubernetes-native H200 clusters that deliver more than hype. The result is AI agility with measurable business outcomes, from accelerated innovation pipelines to optimized infrastructure spend.
The takeaway is simple: the NVIDIA H200 and Kubernetes together redefine what enterprise AI can achieve. For organizations ready to operationalize this power, the right partnership ensures they capture both the technical gains and the strategic outcomes.



More Similar Insights and Thought leadership
No Similar Insights Found
Subscribe today to receive more valuable knowledge directly into your inbox
We are writing frequenly. Don’t miss that.
Subscribe to get updates

Unregistered User
It seems you are not registered on this platform. Sign up in order to submit a comment.
Sign up now