


Semifly: Pioneering Solutions for Telehealth Hurdles
The telehealth industry has witnessed unprecedented growth in recent years, driven by the need for accessible and efficient healthcare. However, with this rapid expansion come…
•

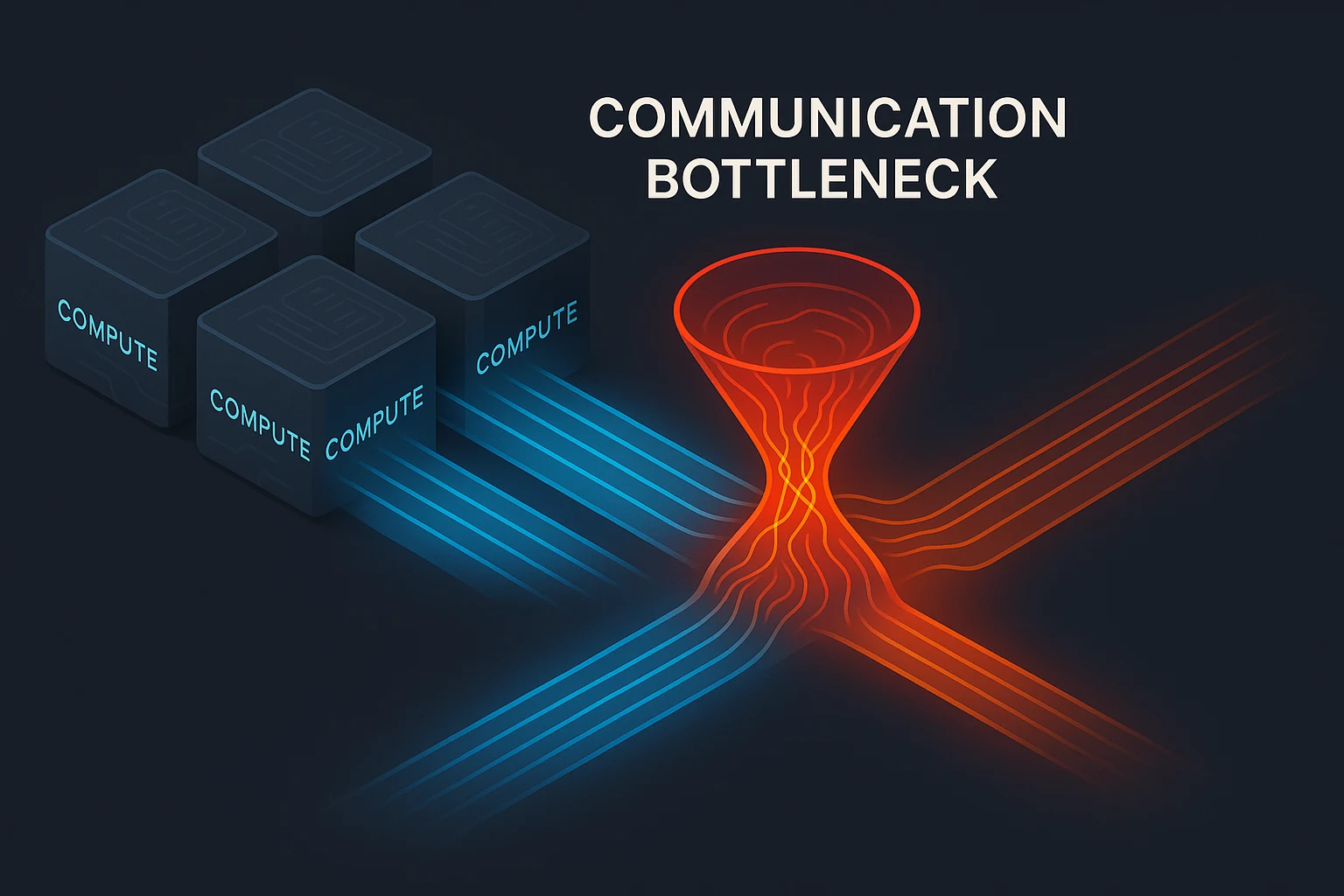
The race to train larger, more sophisticated AI models is no longer just about raw compute—it’s about the speed, efficiency, and reliability of data movement across multi-GPU systems. And in this equation, the combination of NVIDIA H200 and NCCL (NVIDIA Collective Communications Library) is emerging as a critical performance enabler.
The H200 delivers compute. NCCL ensures that compute isn’t wasted waiting for data.
AI workloads today are not confined to a single GPU or server. They span across entire clusters—sometimes across multiple racks and even data centers. Large Language Models (LLMs), generative AI, and real-time inferencing pipelines all require:
Even a small bottleneck in communication can create massive delays. That’s why the shift from “compute-centric” to “communication-aware” system design is in full motion.
The NVIDIA H200 Tensor Core GPU, built on the Hopper architecture, is engineered not only for processing power but also for memory bandwidth and communication optimization. It introduces:
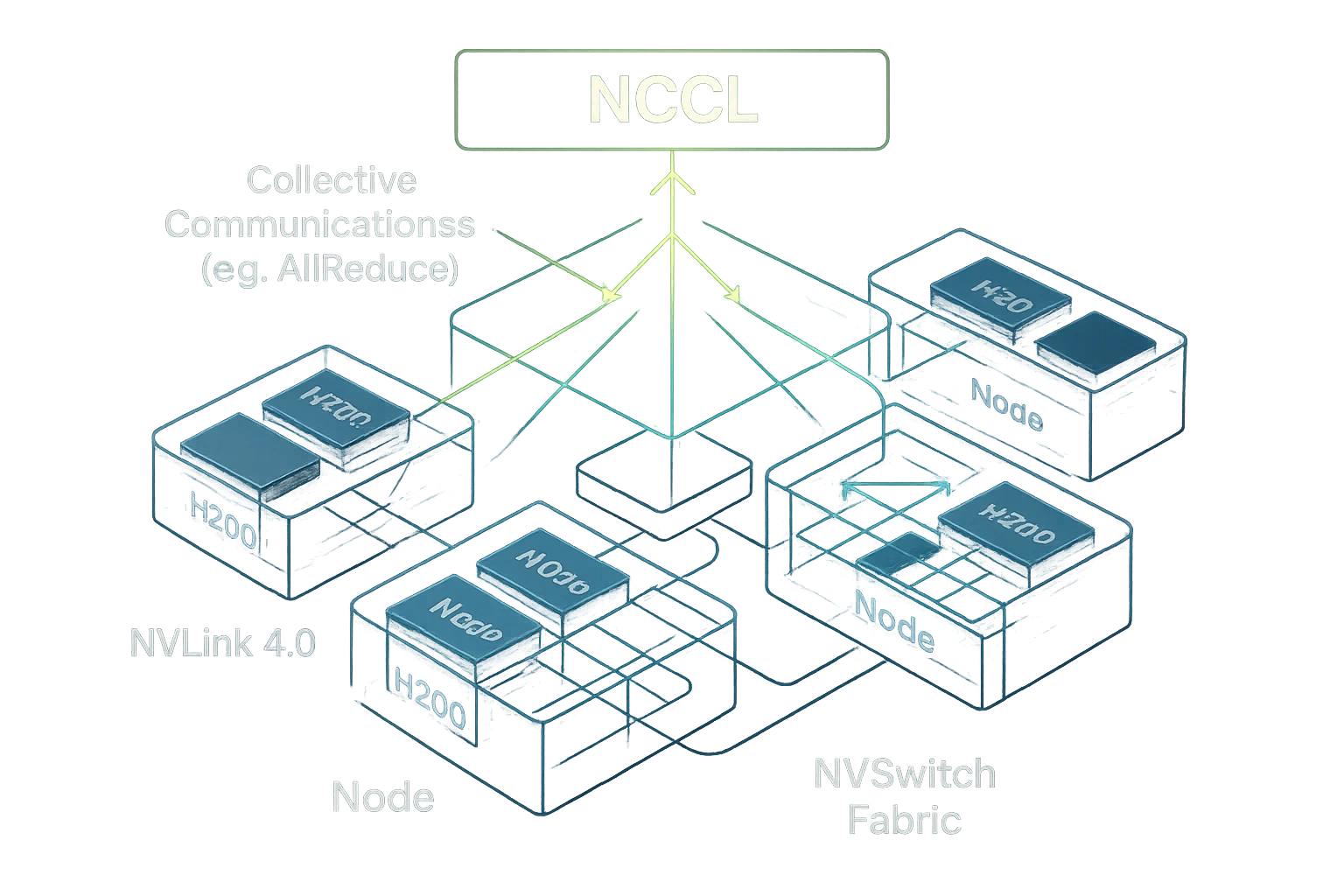
When paired with NCCL, these hardware capabilities unlock collective communication primitives (like AllReduce, AllGather, Broadcast, etc.) at much lower latency and higher throughput.
NCCL is NVIDIA’s optimized library for multi-GPU and multi-node communication, handling all the heavy lifting of synchronizing weights and gradients during training. It supports:
While NCCL can run on older GPUs, its true potential is realized with modern architectures like the NVIDIA H200, where hardware interconnects are designed to support collective ops with minimal overhead.
Table: H100 vs H200 for NCCL Collective Operations
| Feature | NVIDIA H100 | NVIDIA H200 |
|---|---|---|
| HBM Memory Size | 80 GB HBM3 | 141 GB HBM3e |
| Memory Bandwidth | ~3.35 TB/s | ~4.8 TB/s (est. with HBM3e) |
| NVLink Bandwidth | 600 GB/s | 900 GB/s |
| NVSwitch Support | 3rd Gen NVSwitch | 4th Gen NVSwitch |
| NCCL Performance (AllReduce)* | ~950 GB/s (multi-node) | >1.4 TB/s (multi-node est.) |
*Estimates based on vendor benchmarks and internal model scaling results.
Why This Matters: LLM Training, Scaling Laws, and Beyond
Training a model like GPT-4 or Mixtral requires thousands of GPUs communicating tens of terabytes of gradients per second. If your communication layer (NCCL) lags behind, adding more GPUs does not give linear speedup—it just adds cost.
With NVIDIA H200, NCCL can perform operations like AllReduce with less overhead, enabling:
Real-World Impact: Faster Training, Lower TCO
For enterprises building internal LLMs or hyperscalers fine-tuning models at scale, this combo directly reduces:
AI is scaling faster than Moore’s Law. As model sizes explode and deployment timelines shrink, the hardware-software pairing of NVIDIA H200 and NCCL is emerging as a foundational layer in future AI infrastructure.
This isn’t just about speed—it’s about building infrastructure that scales smarter.


We are writing frequenly. Don’t miss that.

Unregistered User
It seems you are not registered on this platform. Sign up in order to submit a comment.
Sign up now