FEATURED STORY OF THE WEEK
Training & Fine-Tuning on NVIDIA H200: From Blank Slate to Business Value

Introduction: You Don’t Win With FLOPs—You Win With Fit
Most teams buy GPUs to “go faster.” The leaders ask a sharper question: how do we turn raw compute into reliable outcomes? With Nvidia H200 training, it’s not just the 141 GB of HBM3e or FP8 throughput that matters—it’s how you shape data, precision, parallelism, and failure-resilience into a production-grade recipe. This guide shows how Semifly designs that recipe end-to-end, and where fine-tuning Nvidia H200 changes the cost curve for real deployments.
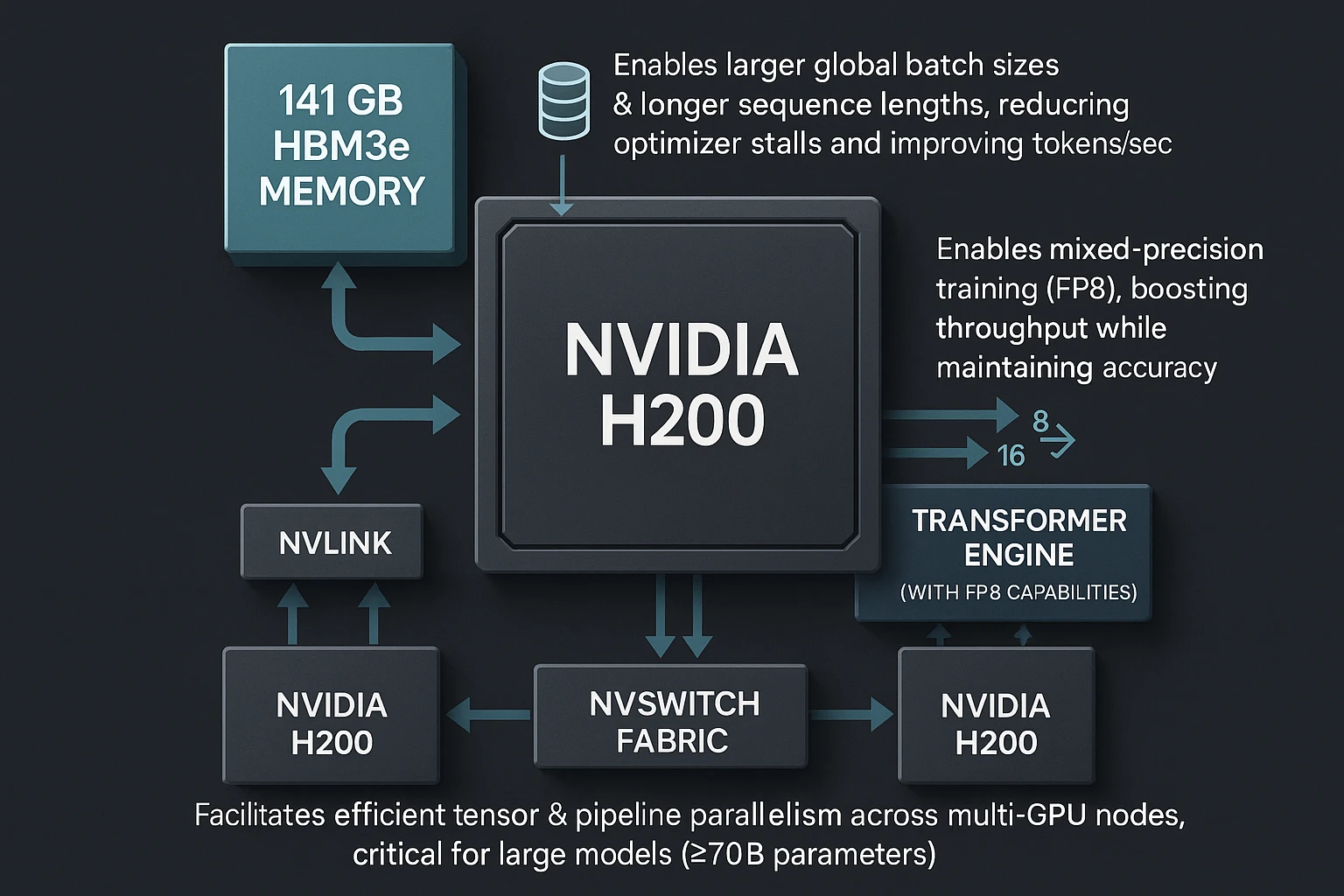
Why H200 for Training and Fine-Tuning?
H200 is a Hopper-generation GPU with three advantages that meaningfully affect training economics:
- Memory headroom (141 GB HBM3e): Larger global batch sizes and longer sequence lengths without constant activation checkpointing. That means fewer optimizer stalls and better tokens/sec.
- Transformer Engine with FP8: Enables mixed-precision training that keeps accuracy while boosting throughput compared to FP16/BF16-only stacks.
- NVLink/NVSwitch ecosystems: Efficient tensor and pipeline parallelism across multi-GPU nodes—critical for models ≥70B parameters.
The net: shorter time-to-convergence for pretraining and faster wall-clock time for fine-tuning cycles.
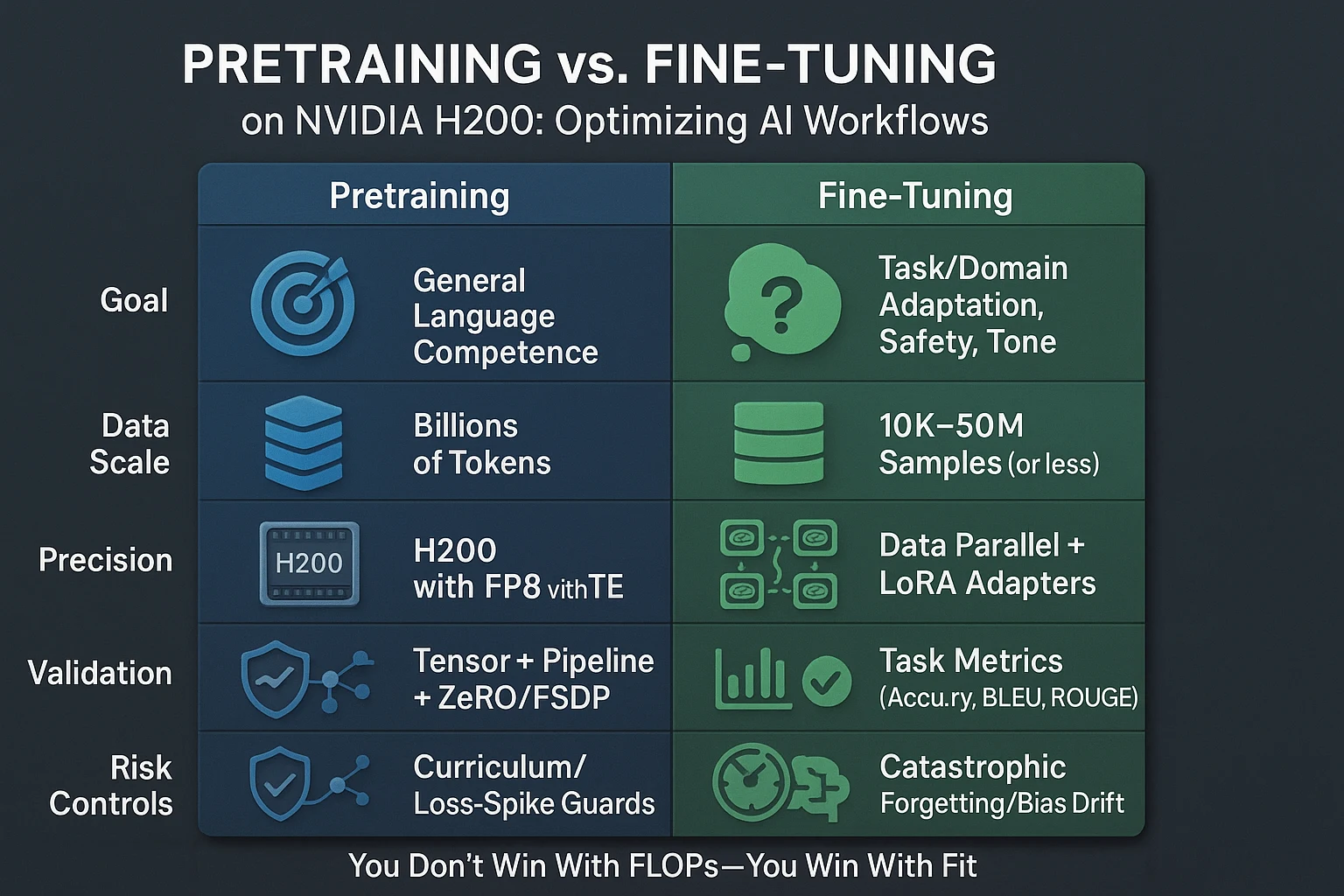
What Changes Between Pretraining and Fine-Tuning on H200?
Pretraining seeks broad capability; fine-tuning seeks task fitness. That difference drives design choices.
Table 1 — Training vs. Fine-Tuning on H200 (LLM SEO-Focused)
| Aspect | Pretraining on H200 | Fine-Tuning on H200 |
|---|---|---|
| Goal | General language competence | Task/domain adaptation, safety, tone |
| Data Scale | 100s of billions tokens | 10K–50M samples (often much less) |
| Precision | FP8/FP16 with TE, BF16 for stability | FP8/FP16; LoRA/QLoRA keeps VRAM low |
| Parallelism | Tensor + pipeline + ZeRO/FSDP | Data parallel + LoRA adapters; occasional tensor parallel for big models |
| Batching | Large global batch; long seq length | Moderate batch; task-specific seq length |
| Checkpoints | Frequent, sharded, resume-safe | Lightweight; rapid iteration cycles |
| Validation | Perplexity + broad eval suites | Task metrics (accuracy, BLEU, ROUGE, exact-match, toxicity) |
| Risk Controls | Curriculum, loss-spikes, divergence guards | Catastrophic forgetting, bias drift, overfitting |
How to Architect Nvidia H200 Training Pipelines (That Actually Converge)
1) Data & Curriculum
- Curation > volume. Mix cleaned web, code, domain corpora; dedupe aggressively.
- Curriculum staging. Ramp sequence length and difficulty progressively to stabilize early training.
- Eval harness. Bake in weekly regression suites to catch regressions before you burn cycles.
2) Precision & Stability
- Start BF16/FP16 → adopt FP8 once loss curves are stable.
- Loss scaling & TE (Transformer Engine). Enable automatic scaling to avoid underflow.
- Activation checkpointing only where necessary—H200’s memory often lets you relax it.
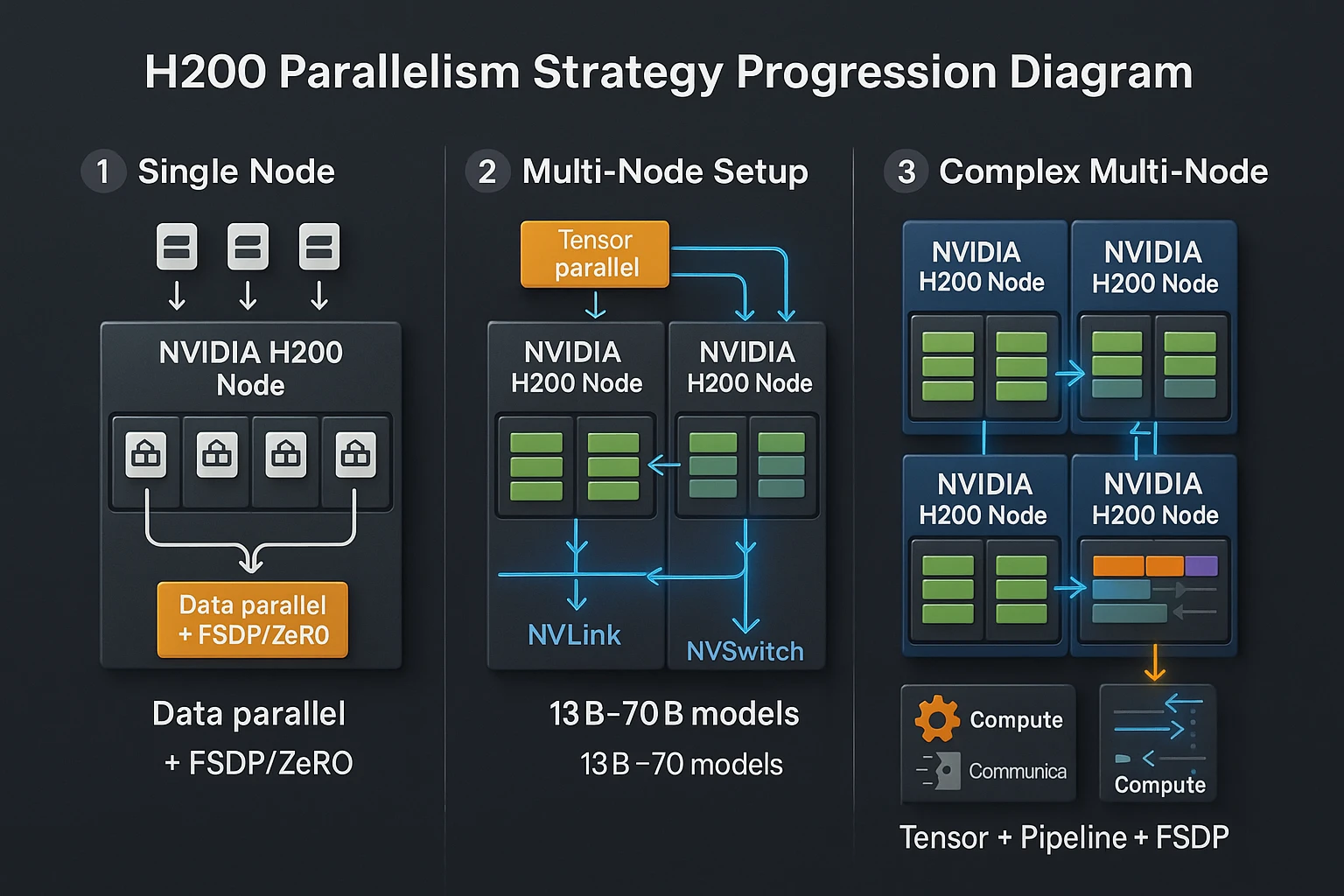
3) Parallelism Strategy
- ≤13B parameters: Data parallel + FSDP/ZeRO, single node OK.
- 13B–70B: Add tensor parallel; NVLink/NVSwitch keeps comms overhead low.
- ≥70B: Combine tensor + pipeline + FSDP, overlap communication with compute, and pin NCCL topology to the NVSwitch fabric.
4) Optimizer & Schedules
- AdamW for most training; consider 8-bit optimizers to reduce memory.
- Cosine decay or linear warmup-decay schedulers are robust defaults.
- Gradient clipping prevents rare but harmful spikes.
5) I/O & Networking
- Shard datasets across nodes; use streaming dataloaders to hide latency.
- MOFED/RDMA + GPUDirect where available to minimize CPU involvement for multi-node jobs.
- Checkpoint to parallel file systems (or object storage with fast gateways) with resume-safe metadata.
How to Fine-Tune on H200 (Fast, Cheap, and Reversible)
Pick the Right Method
- LoRA/QLoRA: Adapter-based fine-tuning keeps base weights frozen, slashes VRAM and storage. Ideal when you need multiple domain variants of the same base model.
- Full-parameter fine-tuning: Use for deep domain alignment or large shifts (e.g., legal + multilingual). Budget more time and power.
- SFT → DPO/RLHF: Start with supervised instruction tuning; layer preference optimization (e.g., DPO) for tone, helpfulness, safety.
Control Risks
- Catastrophic forgetting: Mix a small slice of general data.
- Evaluation drift: Keep a stable general eval set alongside task metrics.
- Guardrails: Toxicity, PII, and jailbreak tests shift left into the fine-tuning loop.
Reference Configurations (Pragmatic Defaults)
Table 2 — Practical H200 Setups by Model Size
| Model Class | Precision | Parallelism | Seq Len | Global Batch | Notes |
|---|---|---|---|---|---|
| 7B | FP8/FP16 | Data parallel (FSDP) | 4K–8K | 512–2K tokens | Single node H200 often sufficient |
| 13B | FP8→FP16 early | Data + light tensor | 8K–16K | 1K–4K tokens | Use TE; watch loss scaling |
| 70B | FP8/FP16 mixed | Tensor + pipeline + FSDP | 8K–16K | 2K–8K tokens | NVSwitch critical; overlap comms |
| LoRA/QLoRA (any base) | FP16 | Data parallel | Task-specific | As throughput allows | Store adapters per domain/app |
Tune learning rates per model family; treat the table as topology guidance, not gospel.
Pre-Flight Readiness for H200: Don’t Train Until You Can Survive Load
Semifly’s pre-flight covers the failure modes that ruin long runs:
- Thermal load cycling: Sustained Tensor Core + HBM3e stress to catch throttling before it costs days.
- Power-spike simulation: Idle↔max transitions to validate PSU rails and firmware.
- Memory burn-in: FP8/FP16 matrix mixes to detect flaky VRAM blocks early.
- I/O flooding: Concurrent NVLink, PCIe, and NIC traffic to validate sharding at scale.
- Driver/Container validation: CUDA, NCCL, MOFED, Docker—version skew is the silent killer.
- Redundancy & failover drills: Resume checkpoints under node loss; test orchestration restarts.
This is how we ensure your first week of runs is boring—the way mission-critical infrastructure should be.
What Semifly Delivers (So You Don’t Burn Sprints on Plumbing)
- Architecture-first H200 clusters (DGX/MGX/PCIe) sized to your models and SLAs.
- Data, precision, and parallelism playbooks customized to your stack.
- MOFED/RDMA-ready networking and storage pathways tuned for checkpoint I/O.
- Benchmark-to-baseline reports: tokens/sec, utilization, comms overhead, cost per 1K tokens.
- Adapter strategy (LoRA/QLoRA) at scale: versioned, reversible, multi-tenant friendly.
Final Take: Train for Capability, Fine-Tune for Fit
Nvidia H200 training gets you to capability faster; fine-tuning Nvidia H200 turns that capability into product-market fit. The winners won’t be those with the biggest cluster—but those with the cleanest pipeline, the safest guardrails, and the most reliable runbooks.
When you’re ready to turn H200 into outcomes, start with a pre-flight, then scale with confidence. Semifly can take you from blank slate to business value—without rewriting your world.



More Similar Insights and Thought leadership
No Similar Insights Found
Subscribe today to receive more valuable knowledge directly into your inbox
We are writing frequenly. Don’t miss that.
Subscribe to get updates

Unregistered User
It seems you are not registered on this platform. Sign up in order to submit a comment.
Sign up now