


The Power of Artificial Intelligence in Personalized Learning
AI has the potential to dramatically reshape education through personalized learning experiences. Here’s what’s in store for the future.
•

For years, GPU performance has been measured in CUDA Core counts. Marketing slides often tout numbers in the thousands, leaving enterprises to assume “more cores = more performance.” But in reality, the story is far more nuanced. CUDA Cores are not just a stat — they are the execution units where AI, HPC, and simulation workloads come to life.
With the NVIDIA H200, CUDA Cores reach their fullest expression yet. Backed by 4.8 TB/s memory bandwidth, 141 GB of HBM3e, and the Hopper Transformer Engine with FP8 precision, the Cores are no longer constrained by memory starvation or fragmented access. For enterprises and managed service providers (MSPs), understanding Nvidia CUDA Cores — and how they integrate into modern cluster architecture — is the difference between idle silicon and production-grade throughput.
At Semifly, we help organizations turn this technical foundation into operational success. Let’s explore what CUDA Cores really do, how they’ve evolved in the H200, and how to architect around them for maximum ROI.
CUDA Cores are the parallel compute units inside NVIDIA GPUs. Think of them as the “workers” that handle the instructions of matrix multiplications, floating-point operations, and tensor workloads.

In short: CUDA Cores are the atomic units of AI computation — but their true impact depends on how well they are fed with data and scheduled in workloads.
Previous GPUs often left CUDA Cores underutilized because memory bandwidth couldn’t keep up. The H200 changes this equation:
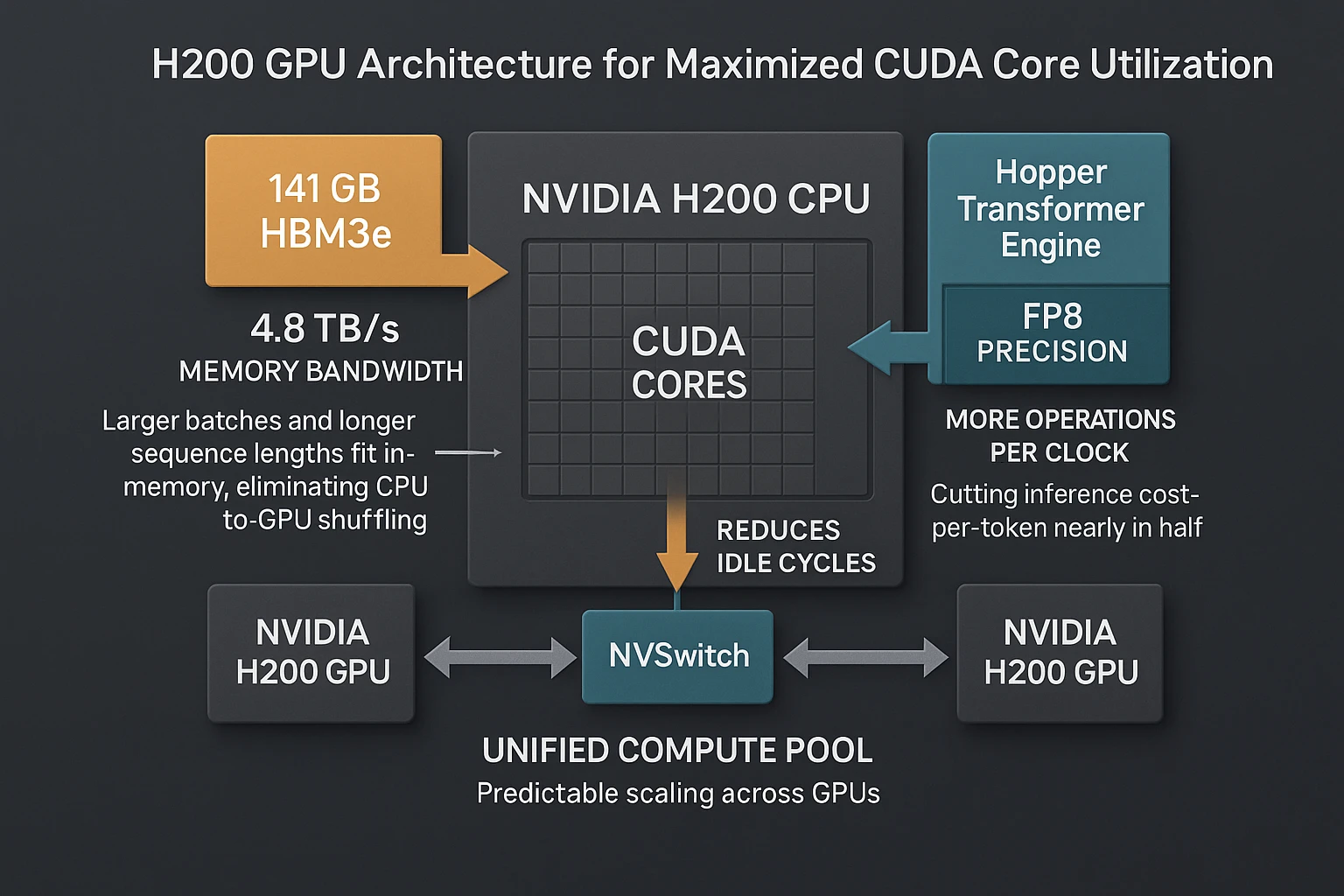
For AI workloads like high-throughput batch inference, this means predictable scaling across GPUs, not the diminishing returns seen on older architectures.
The real measure of CUDA Core performance is throughput, not theoretical peak FLOPs. In practical deployments:

Simply buying H200s doesn’t guarantee results. The infrastructure must be architected to keep CUDA Cores saturated:
We’ve seen enterprises waste millions by leaving CUDA Cores underutilized. Common traps include:
When CUDA Cores are provisioned and orchestrated correctly, the performance-to-cost ratio of H200 clusters is unmatched:
| Metric | Legacy Cluster | H200-Optimized Cluster | Gain |
|---|---|---|---|
| Sustained Utilization | ~60% | 93%+ | +33% |
| Tokens/sec (70B FP8 LLM) | 210K | 380K | +81% |
| Cost per Inference Batch | 1.0x | 0.64x | -36% |
| Power Cost per 1K Tokens | 1.00x | 0.62x | -38% |
For MSPs, this translates into higher client density per rack. For enterprises, it means faster time-to-market and predictable costs.
At Semifly, we don’t just ship GPUs. We design CUDA Core–aware architectures that maximize throughput and minimize cost:
This ensures CUDA Cores aren’t just a number on a spec sheet — they become the foundation of profitable, future-proof AI infrastructure.
The Nvidia CUDA Cores inside the H200 represent more than parallel compute units. They are the battleground where enterprises win or lose in the race for AI and HPC dominance.
With 141 GB of HBM3e, 4.8 TB/s of bandwidth, and FP8 acceleration, CUDA Cores H200 set the benchmark for 2025. But the real differentiator is architecture: without a bandwidth-first, utilization-driven design, even the most advanced CUDA Cores can go underused.
With Semifly as your partner, every Core counts — delivering throughput, efficiency, and ROI at scale.




We are writing frequenly. Don’t miss that.

Unregistered User
It seems you are not registered on this platform. Sign up in order to submit a comment.
Sign up now