For years, data centers have been limited by the tug-of-war between raw GPU performance, memory bottlenecks, and operational efficiency. The NVIDIA H200 changes the equation — not just with faster compute, but with higher memory bandwidth, increased capacity, and better performance-to-cost ratios.
Whether you’re a managed services provider (MSP) or an enterprise architect, getting the most out of H200 is less about just “buying the latest GPU” and more about how you provision, scale, and integrate it into your infrastructure.
From Legacy Bottlenecks to Modern Efficiency
Traditional data center GPU deployments — even with powerful predecessors like the H100 — have faced three recurring challenges:
- Fragmented Memory Access: Workloads that constantly jump across memory blocks slow down throughput and force GPUs to wait for data.
- Bandwidth Saturation: Inadequate interconnect design causes GPUs to idle while waiting for I/O.
- Underutilization: Expensive GPUs running well below capacity due to poor workload alignment or orchestration inefficiencies.

The H200 addresses these pain points with 141 GB of HBM3e memory and 4.8 TB/s bandwidth — but unlocking that power requires an intentional architecture.
How the NVIDIA H200 Changes the Game
Before diving into architecture, it’s important to understand why this GPU changes the operational and financial picture:
- Higher Memory Capacity & Bandwidth: Supports large AI models, multi-modal inference, and HPC workloads without the constant CPU-to-GPU data shuffling.
- Improved Performance-to-Cost Ratio: Better throughput per watt and per dollar, especially for long-running workloads.
- Workload Diversity: Handles everything from generative AI to simulation workloads in the same cluster.
For MSPs, this means delivering more client workloads per cluster and cutting operational costs without sacrificing speed.
Architecting for Maximum Client Density
To turn H200’s specs into tangible MSP advantages, every design choice should prioritize client workload density and cost efficiency:
- High-Bandwidth Interconnect Design
- Deploy NVLink Switch Systems to ensure that multi-GPU workloads run without cross-node latency.
- Design topologies that keep most AI model communication intra-node to reduce networking costs.
- Memory-Aware Workload Scheduling
- Use NUMA-aware GPU scheduling so data remains in the same HBM3e pool during execution.
- Group workloads with similar memory footprints to reduce fragmentation and maximize throughput.
- Tiered GPU Strategy
- Offer premium tiers powered by H200 for high-bandwidth AI and HPC tasks.
- Run lower-priority or less memory-intensive workloads on older GPUs to optimize ROI.
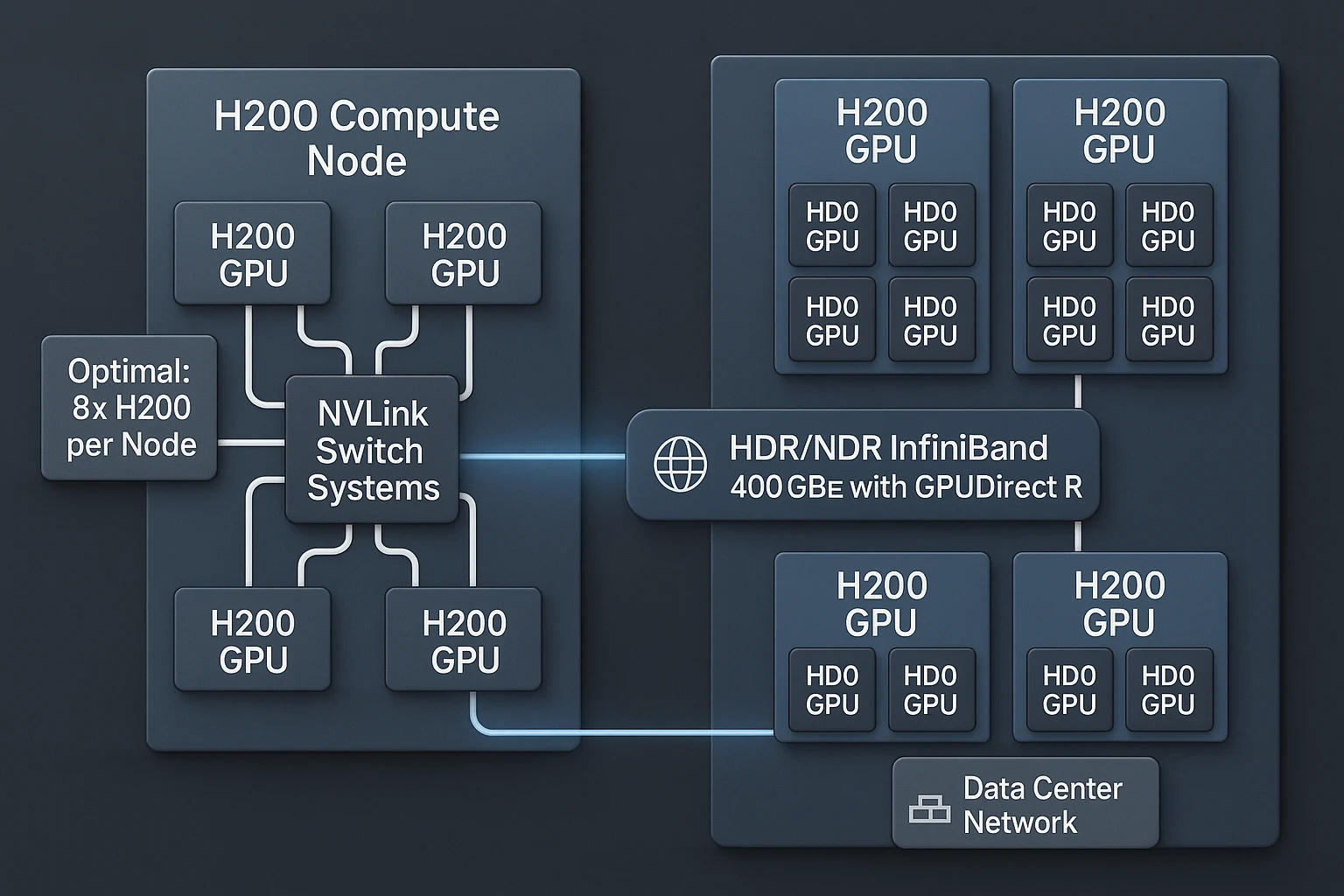
Provisioning an H200 Cluster for ROI and Utilization
A well-provisioned H200 environment can double effective utilization compared to poorly tuned deployments. MSP provisioning best practices include:
- Define Client Workload Profiles: Map each client’s AI/HPC requirements to GPU resource tiers.
- Right-Size Nodes: For most AI training farms, 8x H200 per node is optimal for NVSwitch bandwidth without overheating risks.
- High-Speed Networking: Implement HDR/NDR InfiniBand or 400GbE with GPUDirect RDMA for zero-copy transfers.
- Containerized Orchestration: Kubernetes with NVIDIA GPU Operator for tenant isolation and flexible scaling.
Avoiding Common Pitfalls in MSP H200 Deployments
Even with top-tier hardware, ROI collapses if these are ignored:
- Idle Capacity from Over-Provisioning – Purchase planning must match contract demand.
- I/O Bottlenecks During Checkpointing – Use burst buffers to avoid stalling multi-tenant workloads.
- Memory Fragmentation – Avoid mixing workloads with drastically different memory needs on the same node.
- Thermal Throttling – Proactively manage cooling for sustained performance.
- Outdated Software Stacks – Keep CUDA/NCCL versions aligned with H200 optimizations.
Maximizing Utilization to Increase Margins
For MSP profitability, utilization discipline is the key lever:
- Multi-Tenancy with GPU Partitioning: Use MIG or software partitioning to share GPUs between clients without resource conflict.
- AI-Driven Scheduling: Predict load spikes using historical usage patterns and pre-provision capacity.
- Performance Profiling: Continuously benchmark workloads to spot under-optimized jobs.
- Service-Level Packaging: Sell guaranteed performance tiers based on bandwidth and memory, not just GPU count.
The H200 MSP Advantage in Numbers
When optimized, H200 clusters can deliver:

These gains directly translate into higher margins per rack and more billable workloads per GPU.
Conclusion: Making the H200 Pay for Itself
For MSPs, the H200 is not just about having the fastest GPUs — it’s about designing a service model and technical architecture that keep those GPUs at 90%+ utilization, across diverse client workloads, without overspending on infrastructure.
When paired with bandwidth-aware architecture, workload-specific provisioning, and continuous operational optimization, the H200 becomes a profit multiplier — delivering more workloads, at lower cost, with higher speed.










Unregistered User
It seems you are not registered on this platform. Sign up in order to submit a comment.
Sign up now