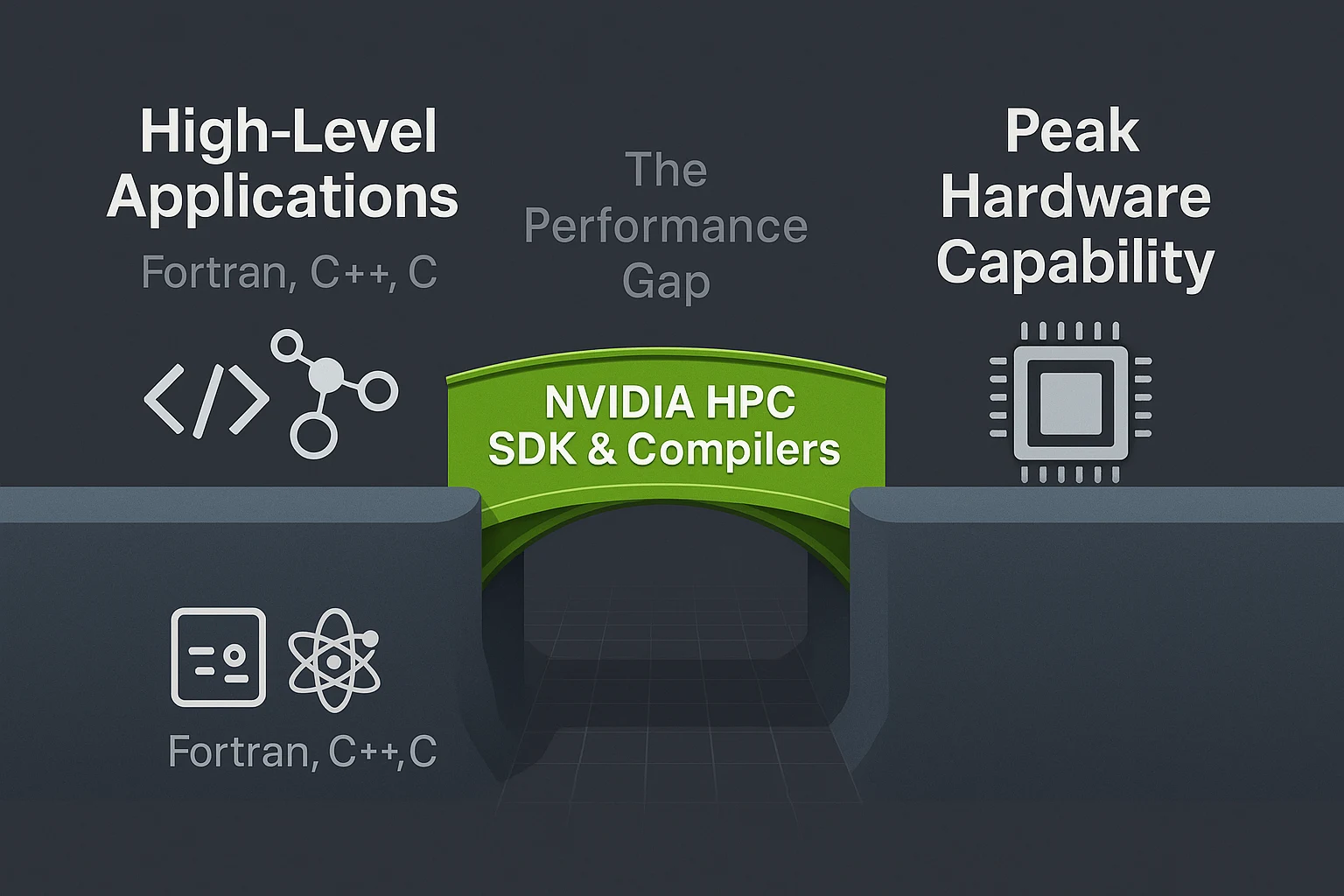
Exascale computing and AI-driven research require more than raw GPU power. The gap between peak hardware capability and real-world performance is widening. Organizations running simulations, machine learning models, or scientific workflows cannot rely on faster processors alone. They need compilers and software toolchains that translate high-level code into efficient CPU and GPU instructions. Without this, advanced hardware risks being underused.
The NVIDIA HPC Compiler, part of the NVIDIA HPC SDK, helps close this gap. It enables performance gains without forcing teams to rewrite entire applications in CUDA, instead supporting directive-based models like OpenACC and OpenMP. For clients in research, engineering, and enterprise IT, compiler technology is a decisive factor in how well hardware investments deliver results. For decision-makers, it shapes performance planning. For technical teams, it provides the bridge between theoretical peak and real application throughput.
1. Setting the Stage: What is NVIDIA HPC (Compiler + SDK)?
The NVIDIA HPC SDK is more than a set of compilers. It is a structured software stack designed to help researchers, engineers, and enterprises translate complex scientific and AI workloads into performance gains on modern GPUs. By combining compilers, optimized libraries, and developer tools, it serves as the bridge between high-level programming models and the hardware capabilities of GPUs such as the NVIDIA H200.
The NVIDIA HPC SDK in a Nutshell
The NVIDIA HPC SDK includes three primary compilers: NVFORTRAN, NVC++, and NVC. These compilers allow developers to build applications in Fortran, C++, and C that can run on both CPUs and GPUs. In addition to compilers, the SDK provides a wide range of mathematical libraries such as cuBLAS (for linear algebra), cuFFT (for fast Fourier transforms), and cuSPARSE (for sparse matrix operations). Together, these tools simplify the process of accelerating compute-intensive workloads across diverse architectures.
Key features make the SDK valuable for organizations adopting GPU-based high-performance computing. It supports GPU acceleration through programming models like OpenACC, CUDA Fortran, and CUDA C++. These models allow developers to annotate existing code with directives or write specialized GPU kernels, depending on project needs. The SDK also delivers CPU performance on multiple processor families, including x86, Arm, and OpenPOWER, ensuring portability across common data center hardware.
Another feature is CUDA-aware MPI with GPUDirect, which enables direct data transfers between GPUs across nodes without routing through system memory. This reduces communication overhead in multi-GPU clusters, improving performance for distributed applications. The SDK also supports container-based workflows using tools like HPC Container Maker and compatibility with Docker or Singularity. This simplifies deployment across shared clusters and supercomputing facilities, ensuring consistency in software environments.
The SDK has its roots in the PGI compiler suite, a respected Fortran and C/C++ compiler stack widely used in HPC for decades. NVIDIA acquired the Portland Group in 2013 and gradually merged its technology into the current SDK. This heritage means that the compilers are mature, reliable, and tested across a wide range of scientific and industrial applications.
The Compiler Component: NVFORTRAN, NVC++, NVC
At the core of the NVIDIA HPC SDK are its three compilers: NVFORTRAN, NVC++, and NVC. These compilers allow developers to write applications in Fortran, C++, and C that can run on both CPUs and GPUs. Each compiler supports GPU offloading, which means portions of the application can be directed to run on the GPU while the remaining code executes on the CPU. This host-device model is essential for achieving balanced performance in high-performance computing workloads.
The compilers support a wide range of directive models, including OpenACC and OpenMP. With these directives, developers can annotate existing code to specify which sections should be accelerated on the GPU, without rewriting large portions of the application. For teams with CUDA expertise, the compilers also support hybrid usage, allowing a mix of CUDA kernels and directive-based programming within the same project.
In terms of target architectures, the NVIDIA HPC compilers are not limited to GPU systems. They can generate executables for CPU-only platforms, GPU-accelerated environments, or hybrid CPU+GPU configurations. This flexibility is valuable for organizations running mixed infrastructure, where applications may need to run on different hardware depending on workload demands.
Performance tuning within these compilers is handled through multiple optimization phases. The compilers perform vectorization (converting scalar operations into vector instructions), loop transformations, and interprocedural optimization, which analyzes code across functions and files to improve performance. The final step is code generation into formats like PTX (Parallel Thread Execution) or LLVM intermediate representation, which the GPU or CPU can then execute efficiently.
An important feature for scientific workloads is automatic GPU mapping. The compilers can detect Fortran array intrinsics or array syntax and map them to GPU-accelerated backends such as cuTENSOR or tensor cores. This reduces the need for manual tuning and ensures that numerical operations benefit from specialized hardware instructions available in GPUs.
By combining directive-based programming with advanced optimization, the NVIDIA HPC Compiler stack helps technical teams bridge the gap between high-level scientific code and hardware-efficient execution. For organizations deploying the NVIDIA H200 GPU, these capabilities are central to ensuring hardware is fully utilized without requiring complete rewrites of legacy applications.
2. How NVIDIA HPC Compilers Work: Architecture and Workflow
Compilation and Offload Workflow
NVIDIA HPC compilers follow a structured pipeline that transforms high-level source code into efficient machine code for both CPUs and GPUs. The process involves multiple stages, each responsible for shaping the code into a form that can be executed effectively on heterogeneous systems.
At the front end, the compiler parses source code written in Fortran, C, or C++. It translates the program into an intermediate representation. This IR is architecture-neutral, meaning it can later be adapted for specific targets. From there, the compiler applies optimization phases such as loop unrolling, vectorization, and interprocedural analysis before generating code tailored for CPUs or GPUs.
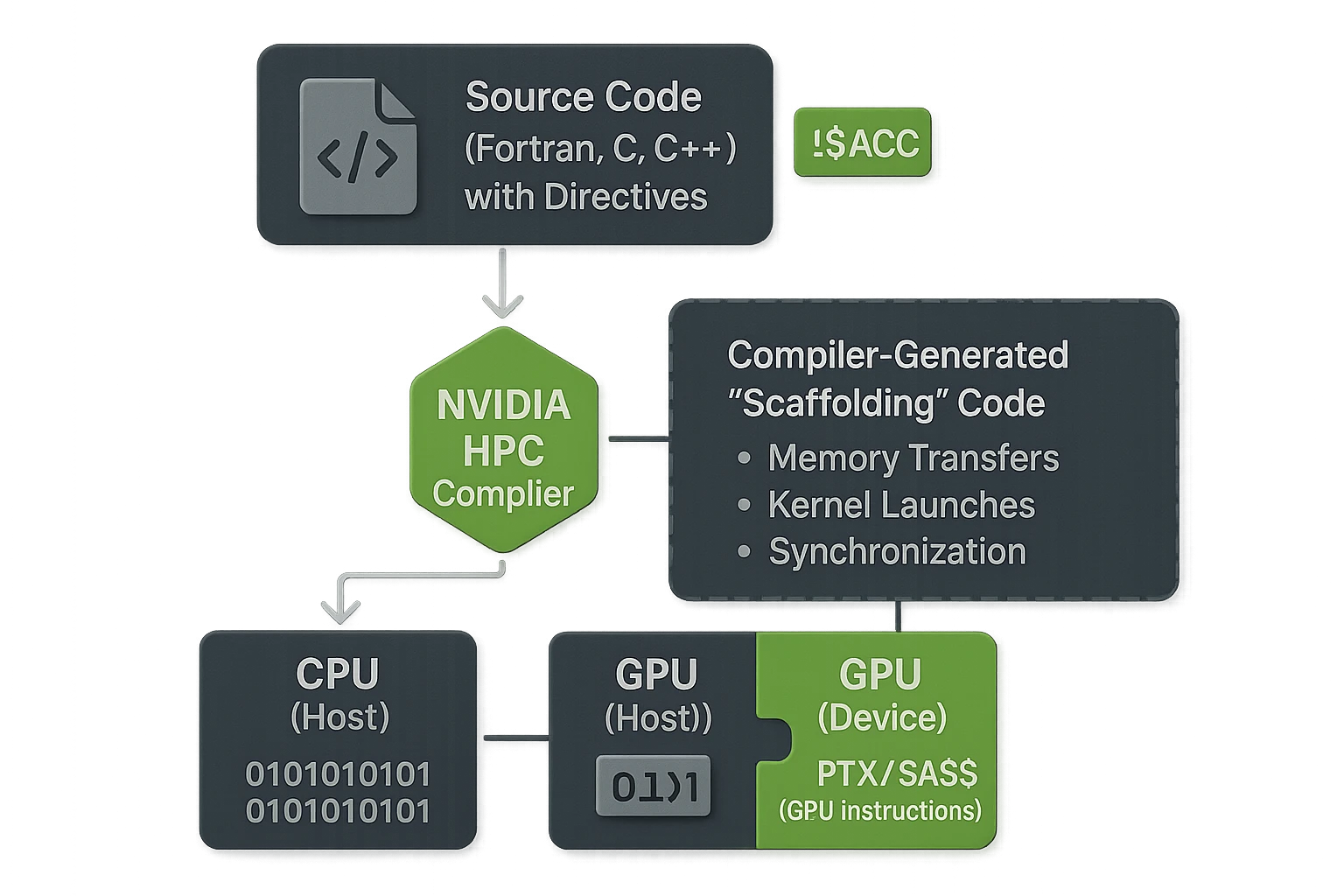
For GPU execution, the workflow involves device compilation. The compiler generates either PTX, a low-level virtual instruction set, or SASS, the actual binary instructions for NVIDIA GPUs. PTX provides flexibility by allowing just-in-time compilation at runtime, while ahead-of-time compilation produces ready-to-execute binaries. This dual approach supports portability across GPU generations while still taking advantage of hardware-specific features.
Execution on GPUs requires careful coordination between the host and the device. The compiler generates scaffolding code for kernel launches, manages memory transfers, and establishes synchronization points. Host-device coordination ensures that data is placed where it is needed, computations are launched on the correct hardware, and results are retrieved efficiently. NVIDIA compilers also handle directive-based offload by lowering high-level constructs into runtime calls. For example, an OpenACC “parallel loop” directive is transformed into a series of runtime instructions that manage GPU execution.
Memory management is a critical part of this workflow. Developers can rely on features like unified memory, where data is automatically accessible to both CPU and GPU, or use more explicit approaches such as pinned memory for faster transfers. The compilers also generate support for asynchronous streams, allowing computation and data movement to overlap. This reduces idle time on both CPU and GPU, improving efficiency in large-scale applications.
Optimizations for Tensor Cores and Mixed Precision
NVIDIA HPC compilers are designed to unlock the full capability of Tensor Cores on GPUs such as the NVIDIA H200. Tensor Cores are specialized hardware units that accelerate matrix operations, which are central to AI training, inference, and many scientific workloads. By targeting these units, the compilers allow applications to achieve higher throughput without requiring developers to write low-level CUDA kernels.
A major part of this process involves mixed-precision computation. The compiler can automatically transform sections of code to use reduced precision formats such as FP16 or FP8 when numerical stability can be maintained. This approach reduces memory bandwidth requirements and increases arithmetic density, leading to faster execution. For applications like deep learning and simulation, this often translates to significant performance gains without major accuracy trade-offs.
The compilers also apply loop-level optimizations to better align workloads with Tensor Core execution. Techniques such as loop tiling, fusion, and unrolling restructure computation so that data is processed in blocks that match GPU hardware constraints. These transformations help ensure that Tensor Cores are consistently fed with data, avoiding stalls and underutilization.
Efficient use of Tensor Cores also depends on the GPU’s memory hierarchy. NVIDIA compilers apply data layout transformations and memory placement strategies to match workloads with the right storage level. Registers are used for the fastest access, shared memory is applied for data reuse within thread blocks, and global memory is managed carefully to reduce latency. In many cases, compilers will automatically map array operations in Fortran or C++ to backend libraries such as cuTENSOR, which are specifically tuned for Tensor Core execution.
Together, these optimizations ensure that Tensor Cores and mixed-precision capabilities are applied in a way that is both safe and effective. For decision-makers, this means that hardware investments in GPUs like the H200 deliver measurable returns across workloads. For technical specialists, it reduces the need for extensive manual tuning, allowing compilers to handle many of the low-level details while still leaving room for expert intervention when required.
Scalability and Multi-GPU/Distributed Execution
High-performance computing often requires scaling beyond a single GPU. Scientific simulations, training large AI models, and engineering workloads must use multiple GPUs within a node or across nodes in a cluster. The NVIDIA HPC compilers and runtime environment support this scaling by combining compiler-level offload features with communication libraries designed for distributed systems.
A core enabler is CUDA-aware MPI that allows direct communication using GPU buffers. This reduces unnecessary memory transfers and improves throughput. When paired with GPUDirect RDMA, GPUs on different servers can exchange data directly over high-speed interconnects such as InfiniBand, avoiding CPU involvement and lowering latency.
Scalability also depends on overlapping communication and computation. The compilers and MPI runtime support asynchronous operations, allowing data transfers and GPU kernel execution to occur in parallel. This overlap ensures that communication does not become a bottleneck, especially in large-scale simulations.
For distributed workloads, strategies such as domain decomposition are commonly used. Here, a problem space is divided across GPUs, with each GPU responsible for a region. Boundary data between regions—known as halo exchanges—must be communicated efficiently between GPUs. The NVIDIA HPC toolchain supports these communication patterns directly, making it easier to scale scientific codes across thousands of GPUs.
Deployment flexibility is another consideration. The HPC compilers allow applications to be built once and shipped with the required runtime in container environments such as Docker or Singularity. This ensures consistent performance across clusters without requiring manual configuration on each node. Containers are particularly valuable for distributed computing because they provide reproducibility and simplify deployment in hybrid or shared environments.
3. The NVIDIA H200: Why This Matters for HPC Compilers
H200 Architecture Overview
The NVIDIA H200 GPU builds on the Hopper architecture and is designed for the largest-scale HPC and AI workloads. It provides significant advances in memory capacity, bandwidth, and computational throughput, all of which directly influence how effectively compilers can extract performance. For teams relying on simulation or machine learning at scale, the H200 marks a substantial improvement over its predecessor, the H100.
A defining feature of the H200 is its 141 GB of HBM3e (High Bandwidth Memory). This not only expands capacity for massive datasets but also raises memory bandwidth to up to 4.8 terabytes per second. For workloads such as large-scale fluid dynamics or transformer-based AI models, higher bandwidth helps reduce memory bottlenecks that often limit GPU throughput.
The H200 retains and enhances Hopper’s Transformer Engine, a hardware component that accelerates mixed-precision AI training and inference. Alongside advanced tensor cores, this makes the GPU particularly effective for both HPC simulations and large language models. Applications compiled with the NVIDIA HPC compilers can target these units directly, ensuring high utilization without requiring extensive manual code modification.
Compiler Implications of H200
The architectural improvements in the NVIDIA H200 have direct implications for how HPC compilers generate and optimize code. Larger memory capacity and higher bandwidth create more headroom for dataset tiling and domain decomposition. Compilers can now break problems into larger tiles or more complex subdomains, which helps distribute computation across multiple GPUs efficiently while minimizing memory transfer overhead.
Tensor core utilization is another critical factor. The H200 features enhanced tensor cores capable of higher throughput and new precision modes such as FP8. Compilers must be able to map operations correctly to these cores, ensuring that matrix operations, convolutions, or AI primitives take full advantage of the available hardware. Automatic mixed-precision transformations, previously applied for FP16 or FP32, may now extend to FP8, enabling performance gains for AI workloads while maintaining acceptable numerical accuracy.
New hardware often introduces instruction sets or capabilities that compilers must target. For the H200, this may include expanded tensor core instructions, additional memory prefetching commands, or optimizations specific to the HBM3e memory architecture. The compiler’s backend must recognize and emit these instructions efficiently to avoid underutilizing the GPU’s potential.
The balance between memory-bound and compute-bound workloads also shifts with H200. Larger memory and faster bandwidth allow deeper inner loops and more extensive kernel execution without stalling for memory accesses. Compilers must adjust optimization heuristics, such as loop unrolling, fusion, or vectorization strategies, to match these new trade-offs. This ensures that kernels remain efficient across both single-GPU and multi-GPU scenarios.
Finally, updated performance models within the compiler are essential. Historical heuristics based on previous GPU generations may no longer accurately predict optimal kernel configurations or tile sizes. Modern compilers for the NVIDIA HPC stack incorporate analytical and empirical models that account for H200’s enhanced memory hierarchy, tensor core throughput, and multi-GPU interconnect capabilities. This enables automatic tuning and better decision-making when offloading workloads, allowing developers to achieve high performance without manually rewriting existing applications.
Synergies between NVIDIA HPC SDK and H200
The NVIDIA HPC SDK is designed to work closely with GPU architectures like Hopper and the H200, allowing compilers to take full advantage of hardware features. By targeting H200-specific capabilities such as advanced tensor cores, enhanced memory bandwidth, and FP8 support, the SDK ensures that applications compiled with NVFORTRAN, NVC++, or NVC are optimized for maximum throughput. This tight alignment between software and hardware reduces bottlenecks and improves performance on both single-GPU and multi-GPU systems.
Future releases of the NVIDIA HPC compiler will include code generation improvements specifically tailored for H200. These updates will automatically exploit new instruction sets, memory hierarchies, and tensor core enhancements, further reducing the need for manual tuning. For developers, this means that workloads can scale efficiently as hardware evolves, without requiring complete rewrites of existing applications.
The software ecosystem readiness for H200 is also supported through NVIDIA AI Enterprise, which now includes the NVL variant of the H200. This means that enterprise software and HPC applications are tested and validated to run on H200 hardware, providing confidence for organizations deploying production workloads.
4. Best Practices for Production Use
Performance Tuning Strategies
Optimizing high-performance applications for NVIDIA H200 GPUs requires careful tuning across both software and hardware layers. The goal is to maximize throughput, reduce idle time, and ensure that expensive compute resources are fully utilized. The NVIDIA HPC compiler and associated SDK provide tools and techniques that make this process systematic and measurable.
The first step is profiling and bottleneck identification. Tools such as NVIDIA Nsight, NVProf, and the HPC SDK’s profiling suite allow developers to pinpoint hotspots in code, measure kernel execution times, and analyze memory utilization. Identifying bottlenecks early informs which kernels or loops require attention, reducing guesswork in performance tuning.

Once hotspots are identified, kernel fusion, loop restructuring, and memory coalescing can be applied. Kernel fusion combines multiple GPU operations into a single kernel launch, reducing launch overhead. Loop restructuring, including unrolling and tiling, helps improve data locality. Memory coalescing ensures that GPU threads access contiguous memory regions, minimizing latency and maximizing bandwidth.
Data transfer management is another critical factor. Overlapping computation with communication using asynchronous copies, pipelining data movement, and leveraging CUDA streams can hide memory transfer latency. This is especially important for multi-GPU or distributed workloads, where PCIe or NVLink transfers could otherwise become performance bottlenecks.
Where numerical stability allows, the use of mixed precision can significantly improve throughput, particularly on Tensor Cores. The compiler can automatically apply mixed-precision transformations to selected code regions, reducing memory footprint and increasing arithmetic intensity without manual rewrites.
Finally, minimizing PCIe and NVLink stalls ensures that GPUs spend more time computing rather than waiting for data. This can be achieved by aligning data transfers with computation, using pinned memory, and tuning kernel launch configurations. By systematically applying these strategies, technical teams can extract predictable performance gains while keeping applications maintainable and portable.
Porting Legacy HPC Codes
Migrating legacy HPC applications to GPU-accelerated systems like the NVIDIA H200 requires a structured and gradual approach. Many existing Fortran or C++ codes were designed for CPU-only execution. A practical strategy is to first compile and run the application in a CPU-only mode using the NVIDIA HPC Compiler. This establishes a verified baseline, ensuring functional correctness before introducing GPU acceleration.
Once the CPU baseline is confirmed, directive-based programming models can be introduced incrementally. OpenACC directives allow developers to mark parallel regions for GPU offload without rewriting entire applications. This stepwise approach helps maintain stability while gradually exploiting GPU resources. In some cases, OpenMP offload may be used for hybrid CPU+GPU execution, depending on compiler support and existing code structure.
Porting also requires careful attention to numerical correctness and stability. Mixed-precision operations, which improve throughput on Tensor Cores, must be applied selectively. Developers should verify that results remain within acceptable error margins, especially for simulation or scientific computing workloads where precision is critical. Automated compiler tools can help identify safe regions for reduced-precision computation.
Finally, testing multiple compiler flags and architecture targets is essential. The NVIDIA HPC Compiler provides options such as -tp to specify target CPU architectures and -gpu to select GPU targets. Running tests across different flags helps identify the optimal configuration for a given workload, balancing performance, memory usage, and kernel efficiency. This iterative tuning ensures that legacy applications can fully exploit the H200’s memory hierarchy, tensor cores, and high-bandwidth interconnects without extensive rewrites.
Support, Maintenance & Risk Management
Enterprise deployments of the NVIDIA HPC Compiler and H200 GPUs benefit significantly from formal support channels. NVIDIA HPC Compiler Support Services offers enterprise-grade assistance, including access to technical experts for bug investigation, guidance on compiler configurations, and escalation paths for critical issues. Organizations can leverage these services to resolve problems quickly, minimizing downtime and protecting project timelines.
Maintaining a stable environment requires careful management of compiler upgrades. Each new release may include performance enhancements, new architecture support, or bug fixes, but upgrades can also introduce regressions. Rigorous regression testing and code validation ensure that applications continue to produce correct results and maintain performance after compiler updates. Enterprise teams should adopt structured testing protocols to verify both numerical accuracy and throughput across all workloads.
Organizations must also consider vendor lock-in risks. While NVIDIA HPC compilers are optimized for NVIDIA GPUs, some enterprises maintain heterogeneous environments with non-NVIDIA hardware. Planning for fallback or alternative execution paths—such as CPU-only compilation or open-source compilers—helps maintain flexibility and avoids dependency on a single vendor. This approach supports business continuity and future-proofing of HPC workflows without compromising current performance.
Conclusion
The NVIDIA HPC compiler stack represents a complete solution for high-performance computing and AI workloads. It extends beyond simple GPU compilation to include directive-based offload, highly optimized libraries, and support for multi-GPU communication and hybrid CPU and GPU execution. When paired with the NVIDIA H200 GPU, which offers higher memory capacity, increased bandwidth, and enhanced tensor core features, the compiler can unlock substantial performance improvements, but only when applications are carefully tuned and compiled with the right strategies.
For enterprise teams, achieving these gains requires a disciplined approach. Profiling workloads, incrementally migrating legacy codes, applying optimization flags, and verifying numerical accuracy are essential steps. Additionally, investing in support services, regression testing, and environment consistency ensures that software updates or new hardware releases do not disrupt operations. In combination, these practices allow organizations to fully leverage the NVIDIA HPC compiler and H200 GPUs, translating raw hardware potential into measurable throughput and efficiency for complex HPC and AI applications.








Unregistered User
It seems you are not registered on this platform. Sign up in order to submit a comment.
Sign up now