Universities are under increasing pressure to advance research in medicine, climate science, and artificial intelligence. These disciplines depend on processing massive datasets and running complex simulations. Traditional CPU-based computing often struggles to deliver results fast enough to meet the pace of modern academic demands. This performance gap has pushed institutions to adopt GPUs as a core component of their research infrastructure.
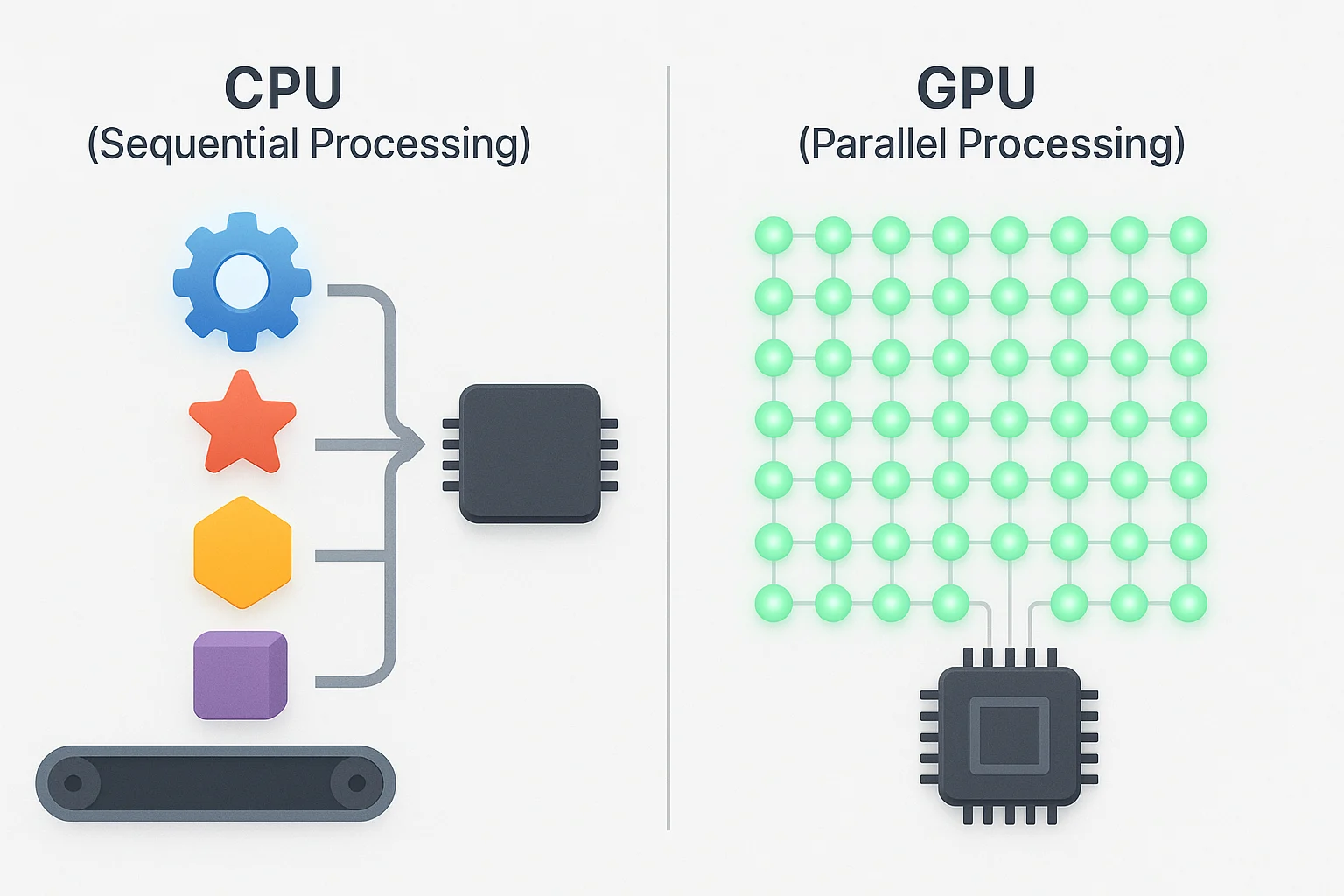
GPUs are designed to handle parallel processing, which allows them to execute thousands of calculations simultaneously. They are well-suited for tasks such as large-scale data analysis, AI model training, and real-time simulations. For academic research, this represents a practical step forward in supporting both established fields like physics and biology, as well as emerging areas such as AI-driven social sciences.
1. How Are GPUs Accelerating University Research?
GPUs have become a cornerstone of modern academic research because of their ability to execute thousands of parallel operations simultaneously. Their impact can be seen across life sciences, climate research, and even the humanities.
Life Sciences: Protein Folding and Drug Discovery
In medical and biological research, protein folding has long been a bottleneck. Traditional CPU-driven methods struggled to capture the complexity of protein interactions. With GPU acceleration, universities can now run simulations that reveal how proteins fold and interact with potential drugs in a fraction of the time. This not only accelerates drug discovery but also reduces the cost of experimentation, enabling institutions to expand the scale of their research.
Climate Science: Large-Scale Modeling
Climate science demands processing vast geospatial and atmospheric datasets, often requiring months of computational time on conventional systems. GPUs have changed this dynamic by enabling higher-resolution models to run more quickly and efficiently. Universities now use GPU-accelerated systems to study long-term climate shifts, predict extreme weather patterns, and simulate the impact of interventions such as carbon reduction strategies. This capability is critical as climate data grows more complex and urgent for global research agendas.

Humanities and Social Sciences: Language and Cultural Studies
In the humanities and social sciences, universities are applying GPU acceleration to train large language models. These models help researchers analyze linguistic structures, study cultural texts at a scale, and improve machine translation systems. For example, GPU-driven LLMs allow social scientists to explore patterns in large text datasets, providing fresh insights into societal change and communication trends.
A Broader Academic Impact
Across these diverse applications, GPUs in university research are enabling progress that was once out of reach. From accelerating drug discovery to advancing climate models and enhancing cultural studies, GPUs provide the computational speed and efficiency required for deeper, faster insights. They are not just improving outcomes in individual disciplines; they are reshaping the way universities approach discovery itself.
2. Why NVIDIA H100 Matters for Universities
In university research settings, every fraction of performance matters. The NVIDIA H100 GPU delivers advantages that extend far beyond raw compute power. For decision-makers and technical leaders, here’s a deeper look at why the H100 is a strategic choice for research institutions.
High Memory Bandwidth and Advanced Tensor Cores
At its core, the H100 is built on the Hopper architecture, featuring fourth-generation Tensor Cores and a specialized Transformer Engine that dynamically balances precision (e.g., FP8, FP16) to maximize throughput without sacrificing accuracy.
- In large language model training benchmarks (e.g., GPT-3 scale), the H100 can deliver up to 4x faster training throughput compared with previous generation GPUs.
- For inference workloads, the H100 claims 30x speed-up over older architectures in some use cases.
- The GPU supports double-precision (FP64) operations suited for traditional HPC tasks, with 60 TFLOPS FP64 Tensor Core performance in some configurations.
- Memory bandwidth is extremely high — for SXM form factors, around 3.35 TB/s — ensuring data can flow in and out of cores at scale.
- In practice, this means research workloads—whether training deep neural networks, solving differential equations, or doing multi-scale simulations—are less bottlenecked by memory access or data movement.
Efficiency and Power Per Computation
Universities often operate under tight budgets and power constraints. The H100’s efficiency gains can, therefore, translate into real cost savings and a reduced environmental footprint.
- Transitioning from CPU-only compute to GPU-accelerated systems has been estimated to save over 40 terawatt-hours of energy annually in AI and HPC workloads.
- Empirical studies on 8-GPU H100 nodes show that during heavy AI training, the maximum observed power draw was about 8.4 kW, which is around 18% lower than the manufacturer’s 10.2 kW rating.
- The H100 supports Multi-Instance GPU (MIG) partitioning, letting a single GPU be subdivided into up to seven isolated instances. This enables better utilization and energy proportionality (i.e., only powering what is needed).
For universities aiming to contribute to sustainability goals, these efficiencies make a compelling case: more performance, less waste.
Enabling Large-Scale Research Projects
The true value of the H100 lies in how it expands what researchers can attempt and achieve.
- In genomics and computational biology, model sizes and datasets are exploding. The H100’s memory size and high throughput let researchers run larger models (e.g., full-genome simulations) in reasonable timeframes.
- In computational chemistry and materials science, methods such as density functional theory, molecular dynamics, and quantum Monte Carlo can benefit from mixed-precision tensor cores while retaining necessary scientific accuracy via fallback to full-precision paths.
- In deep learning and AI research, NVIDIA H100 lets institutions host training of models with billions of parameters. For language, vision, and multimodal models, this opens the door to pushing scientific boundaries from within the university, not just in industry labs.
- Coupling H100 GPUs into DGX systems (e.g., DGX H100 with 8 GPUs) gives institutions a turnkey platform for high-performance workloads with preintegrated interconnect, cooling, and software stack support.
Because the architecture supports both AI and HPC use cases, universities avoid fragmentation. The H100 becomes a convergence point for diverse disciplines.
3. Beyond Hardware: GPUs in Curriculum and Learning
The adoption of GPUs in universities is not limited to research facilities. Their influence is increasingly visible in classrooms, where they are reshaping how students learn computer science, engineering, and applied AI.
Embedding GPUs into Academic Programs
Traditional coursework in machine learning and computational science often focused on theoretical principles. While essential, these foundations left a gap between classroom learning and the demands of real-world projects. By embedding GPUs in university research and training, institutions provide students with hands-on experience in scaling models, optimizing training performance, and working with large datasets.
Role of the NVIDIA Deep Learning Institute
The NVIDIA Deep Learning Institute (DLI) plays a central role in bridging this gap. It provides universities with access to GPU-powered curricula, online labs, and instructor resources. Courses range from computer vision and natural language processing to scientific computing. Each module emphasizes practical experimentation on GPUs, ensuring students learn to design, train, and deploy models effectively.
By offering structured, GPU-enabled coursework, the DLI helps universities align academic content with the tools used in industry and advanced research labs. This ensures graduates can transition seamlessly into professional and research environments.
Table: AI and GPU-Enhanced Courses in Universities
| University |
Course/Program |
GPU Utilization |
| Stanford University |
CS229: Machine Learning |
GPU-backed deep learning |
| MIT |
Computational Biology & AI |
Genomics simulations on GPUs |
| University of Oxford |
AI for Social Good |
Large-scale NLP on GPUs |
4. Challenges Universities Face with GPUs
Even though GPU technology offers enormous advantages for research, many universities encounter serious obstacles when trying to adopt and scale GPU infrastructure. Below is a deeper look at these hurdles and why they can derail GPU adoption if not addressed strategically.
High Upfront Cost of GPU Clusters
- Acquiring GPU clusters demands significant capital investment. The cost is not limited to the GPUs themselves: it includes servers, high-speed interconnects (e.g., NVLink, InfiniBand), storage, cooling, and power infrastructure.
- Many institutions delay upgrades because operating budgets do not readily absorb large one-time expenditures.
- Leasing or purchasing high-end GPUs often requires multi-year commitments, which clashes with shorter funding cycles standard in academia.
- Moreover, expansion of capacity is not linear: adding a few GPUs might force upgrades of facility power capacity or cooling systems.
- Some institutions offset this by charging internal “compute fees” to research groups, but this can discourage usage or force researchers toward external (cloud) options.
Because of these factors, GPU clusters can remain small relative to demand, creating resource contention as workloads grow.
Rigid IT Spending in Universities
Unlike enterprises, universities manage IT within far more rigid financial structures. Spending is typically tied to competitive grants, government appropriations, or endowment income, all of which come with restrictions on how funds can be used. This makes procurement cycles slower and limits flexibility compared to enterprise environments.
While companies often evaluate GPU clusters in terms of revenue-driven ROI, universities assess them through Total Cost of Ownership (TCO). TCO in higher education extends beyond hardware acquisition to include facilities, energy use, staffing, software licensing, and lifecycle management. Studies of university IT systems show that the initial purchase often accounts for less than a quarter of long-term costs, with operations and maintenance consuming the majority.
For administrators, the real challenge is not simply acquiring GPUs but sustaining them over many years under constrained budgets. As a result, many institutions underinvest in on-premises infrastructure and increasingly rely on shared clusters, consortia, or cloud credits to spread costs more effectively.
Complexity in Managing HPC and AI Workloads
Running GPU clusters is more than just buying hardware; it introduces a level of system complexity that many universities have not mastered yet.
- Job Queuing Delays: With many users sharing limited GPU resources, queue times can stretch for days, slowing research timelines. The “GPU bottleneck” is a commonly reported issue in academic environments.
- Heterogeneous Hardware: Clusters often evolve incrementally. This leads to a mix of GPU generations in one system, complicating scheduling, software support, and performance predictability. Some nodes may underperform relative to newer ones, creating coordination challenges.
- Energy and Idle Costs: When nodes or GPUs are idle, they still consume power and cooling overhead. Inefficient allocation can inflate energy bills.
- Software Stack and Compatibility: GPU workloads rely on a complex stack—drivers, CUDA, libraries (cuDNN, NCCL), frameworks (TensorFlow, PyTorch), scheduling systems (Slurm, Kubernetes) and orchestration. Ensuring compatibility across versions and nodes is an ongoing burden.
Altogether, managing such complexity requires specialized IT skills, robust system design, and continuous tuning. Many universities underestimate the ongoing operational load.
Need for Skilled Faculty and Administrators
It is not enough to have GPUs and a good cluster architecture. People matter and many institutions lack the required human capital.
- Faculty and researchers may have domain expertise but limited practical experience in large-scale GPU programming, optimization, or cluster-level resource constraints.
- Administrators or IT staff often come from traditional compute or database domains; they may lack experience with parallel computing, GPU internals, or AI workflows.
- Training and retaining staff is essential and costly. Universities must invest in professional development, mentorship, and sometimes partnerships with vendors (e.g., NVIDIA) to build competency.
- Because GPU systems evolve rapidly (new architectures, precision formats, interconnects), continuous education is required rather than a one-time upskilling.
Without capable personnel, even well-funded GPU systems can underperform, be misconfigured, or see low adoption.
5. Key Recommendations for Universities
Adopting GPU infrastructure and curricula in universities is a strategic undertaking. The following recommendations aim to help institutions maximize return on investment, avoid common pitfalls, and build sustainable GPU-enabled research and teaching environments.
Invest in Shared GPU Clusters
A shared cluster model helps distribute cost and increase utilization across departments. Rather than each lab or department procuring its own small GPU system, universities should centralize GPU assets and provide “compute as a service.”
- Cost Sharing and Governance: Establish a central budget or cost-recovery model where departments contribute based on usage. This discourages isolated, underutilized GPU silos.
- High Utilization: Shared clusters typically see better load balancing, fewer idle GPUs, and improved ROI.
- Maintenance and Support Centralization: A shared infrastructure can justify hiring dedicated GPU / HPC staff and streamline software management.
- Multi-Instance Partitioning: Use technologies such as NVIDIA’s Multi-Instance GPU to subdivide GPUs for smaller workloads. This enables multiple users to run jobs concurrently without requiring full GPU capacity.
A shared cluster can also serve teaching, student projects, and departmental prototypes, not just faculty research.
Forge Partnerships with Technology Vendors
Working with GPU vendors, cloud providers, or HPC vendors can unlock financial, technical, and ecosystem advantages for universities.
- Grant and Donation Programs: For example, NVIDIA’s Academic Grant Program offers hardware, software, and cloud credits to research teams.
- Educational Pricing and Discounts: Many vendors offer discounted rates for academic use or bulk purchases.
- Collaborative Research Labs: Partnerships often include access to early hardware, joint research programs, and co-publication opportunities. NVIDIA maintains academic research collaborations with universities worldwide.
- Cloud Vendor Credits: AWS offers the Cloud Credit for Research program, where faculty and research staff can apply for AWS usage credits for data-intensive research.
Through these arrangements, universities can defer capital costs and tap into vendor expertise during deployment and operation.
Embed GPU Training into Curricula
Infrastructure investments must be accompanied by a strategy to develop human capacity. GPU computing should find its way into academic programs, from introductory courses to advanced electives.
- GPU Programming and Architecture Courses: Offer modules or electives that teach CUDA, parallel programming, and optimization techniques.
- Hands-on Labs Using GPU Infrastructure: Encourage students to run experiments on real GPU clusters rather than solely relying on simulations or toy problems.
- Use of Vendor Training Resources: Leverage materials from NVIDIA (e.g., Deep Learning Institute), AWS Educate, or other provider platforms.
- Project-Based Learning: Encourage student projects that involve real-world data and AI models, reinforcing the need to think about performance, memory, scalability, and resource constraints.
By embedding GPU experience into the curriculum, universities ensure students graduate ready to work in both research and industry roles.
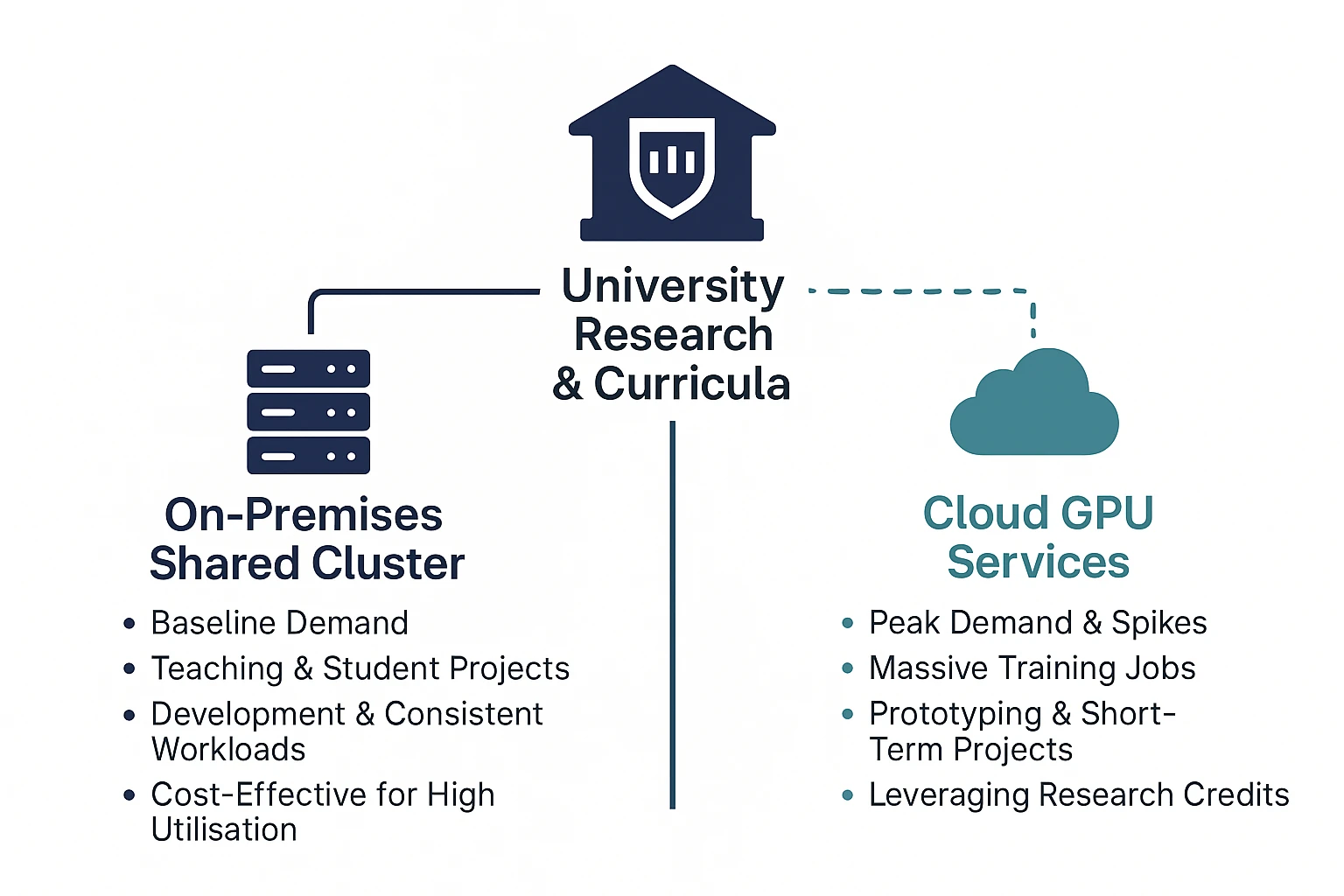
Adopt Hybrid Models: On-Premises Combined with Cloud
No single infrastructure model suits all workloads. A hybrid approach offers flexibility and resilience.
- On-Premises Clusters for Baseline Demand: Use local GPU clusters for consistent, predictable workloads, and for development and teaching use.
- Cloud Bursts for Peaks: For spikes, massive training jobs, or prototyping, offload to cloud GPU services. This avoids overprovisioning on campus.
- Cloud Credit Programs: As noted, AWS, Google Cloud, and other providers often extend research or educational credits to institutions, reducing marginal cost.
- Cost-Efficiency Techniques: Use spot or preemptible instances in the cloud for non-critical training tasks, combined with checkpointing to guard against interruptions.
- Interoperability and Portability: Design software and pipelines so workloads can run both locally and in cloud environments with minimal change (e.g., containerized jobs, consistent orchestration).
A hybrid strategy helps universities manage risk, scale elastically, and avoid stranded hardware resources.
Wrapping Up: The Strategic Role of GPUs in University Research
GPUs have moved from being supportive tools to becoming a foundation of modern university research. As data volumes grow and AI models expand, the ability to process complex workloads quickly and efficiently is now critical for academic competitiveness. Institutions that lack high-performance computing resources risk limiting their researchers to scaled-down experiments, while their peers advance in fields such as climate science, genomics, and natural language processing.
The NVIDIA H100 has emerged as a key accelerator in this shift. With high memory bandwidth, advanced tensor cores, and improved energy efficiency, it allows researchers to take on projects that were previously out of reach. It enables a convergence of AI and traditional high-performance computing, creating opportunities for cross-disciplinary discovery that span engineering, medicine, and the social sciences.
For institutions, the message is clear. Expanding both hardware investments and curricula around GPUs in university research will strengthen their leadership in discovery, innovation, and talent development.









Unregistered User
It seems you are not registered on this platform. Sign up in order to submit a comment.
Sign up now