Building powerful AI solutions is a major challenge for businesses today. Many struggle with complex infrastructure. Setting up the right mix of compute, networking, and storage for demanding AI tasks like training large language models is difficult and time-consuming. Scaling this infrastructure as needs grow often leads to integration headaches and wasted resources. This complexity slows down innovation.
The NVIDIA DGX BasePOD™ solves these problems. It is a pre-tested, ready-to-deploy blueprint for enterprise AI infrastructure. Developed by NVIDIA and its partners, it provides a complete, end-to-end setup. This means businesses get a fully designed system covering powerful computers, fast networking, efficient storage, and essential software, all optimized to work perfectly together from day one.
This blueprint integrates cutting-edge components like the NVIDIA H200 Tensor Core GPU. The H200 delivers immense computing power needed for next-generation AI. The NVIDIA DGX BasePOD™ ensures these advanced GPUs work seamlessly within the larger system, maximizing performance.
The purpose of this blog is straightforward: to explore how the NVIDIA DGX BasePOD™ simplifies deploying enterprise-scale AI. It removes the guesswork, reduces setup time from months to weeks, and provides a clear, scalable path for AI projects of any size.
1. What is NVIDIA DGX BasePOD™?
Building enterprise AI infrastructure can be complex and risky. The NVIDIA DGX BasePOD™ is designed to solve this problem. It is a ready-made blueprint for powerful AI computing systems. Think of it as a detailed, pre-approved plan created by NVIDIA and its technology partners. This plan tells you exactly which components work best together.
At its heart, the NVIDIA DGX BasePOD™ aims to make AI deployment standard and reliable. It uses NVIDIA’s own powerful DGX computers as the foundation. The magic is in how it optimizes every part of the system. This includes the computers themselves, the networking that connects them, the storage for data, and the software that runs everything. This full-stack approach ensures all pieces work perfectly in harmony.
One major goal of the NVIDIA DGX BasePOD™ is to drastically reduce setup time. Instead of taking many months to design, test, and build a custom AI system from scratch, businesses can deploy a BasePOD™ in just weeks. This blueprint handles all the complex integration work upfront.
Another key objective is scalability. You can start with a small system using just a few NVIDIA DGX computers, perhaps with four or eight powerful GPUs. As your AI projects grow and need more computing power, the NVIDIA DGX BasePOD™ design lets you easily add more units. It can reliably scale up to connect thousands of GPUs working together.
Finally, the NVIDIA DGX BasePOD™ eliminates compatibility risks. Mixing hardware and software from different vendors often leads to problems and wasted time. Because every component in the BasePOD™ blueprint is pre-tested and validated by NVIDIA, you know everything will work together smoothly right from the start.

2. Why is NVIDIA DGX BasePOD™ Critical for Modern AI Workloads?
Today’s AI workloads demand immense computing power and seamless coordination. Many enterprises struggle with disconnected systems, underused hardware, and isolated data. This slows down AI projects and inflates costs. The NVIDIA DGX BasePOD™ tackles these problems head-on by delivering a unified, efficient infrastructure.
One major pain point is fragmented infrastructure. Mixing different brands of servers, networks, and storage often causes bottlenecks. The NVIDIA DGX BasePOD™ solves this with a pre-integrated design. Every component—from DGX systems to software—is tested to work perfectly together, eliminating compatibility issues and delays.
The blueprint also maximizes resource usage. Traditional setups often leave expensive GPUs idle due to poor workload balancing. The NVIDIA DGX BasePOD™ optimizes utilization through intelligent orchestration, ensuring every processor is efficiently engaged. This reduces waste and boosts ROI.
Siloed data is another hurdle. When information is trapped in separate storage systems, AI models train slower. The NVIDIA DGX BasePOD™ unifies data access with high-speed storage, letting AI tools seamlessly analyze massive datasets across the entire cluster.
It’s specifically engineered for demanding workloads. For large language models (LLMs), which require thousands of GPUs working in sync, the NVIDIA DGX BasePOD™ provides predictable scaling. Its networking design prevents slowdowns during model training.
Generative AI tasks—like creating images or text—and high-performance data analytics (HPDA) need rapid data processing. HPDA means analyzing huge datasets at extreme speed. The blueprint’s balanced architecture prevents bottlenecks, accelerating these workloads.
For multi-tenant AI clouds, where multiple teams share resources, the NVIDIA DGX BasePOD™ enforces strict isolation. This keeps projects secure and prevents one team’s heavy workload from affecting others.
The NVIDIA H200 GPU amplifies these benefits. With 141GB of ultra-fast memory (HBM3e) and 4.8TB/s bandwidth, it handles massive AI models that older GPUs cannot. Inside the NVIDIA DGX BasePOD™, H200s work in concert, slashing training times for trillion-parameter models.
3. How Does NVIDIA DGX BasePOD™ Integrate the NVIDIA H200 GPU?
The NVIDIA H200 GPU is a powerhouse for AI, and the NVIDIA DGX BasePOD™ is built to harness its full potential. This integration transforms how enterprises handle massive AI workloads. Let’s explore how they work together.
- Hopper Architecture: The NVIDIA H200 uses NVIDIA’s latest Hopper architecture. A key feature is its support for FP8 precision, a data format that allows faster calculations while maintaining accuracy. This enables up to 2x faster AI training compared to previous-generation GPUs like the A100. Complex models get trained in half the time.
- Compatibility with BasePOD™: Compatibility is seamless because the NVIDIA DGX BasePOD™ uses a unified fabric called NVLink/NVSwitch. Think of this as a superhighway connecting GPUs. It lets the NVIDIA H200 share data with other GPUs in the system at incredible speeds, avoiding bottlenecks that slow down traditional setups.
- Seamless Scaling: Scaling is also effortless. The NVIDIA DGX BasePOD™ links multiple DGX H200 nodes (servers containing H200 GPUs) into a single cluster. AI workloads automatically distribute across all available NVIDIA H200 GPUs. Whether you start with 8 GPUs or 100, the system grows without reconfiguration.
- Optimized Memory Pooling: Memory pooling is another breakthrough. The NVIDIA H200’s massive 141GB memory (HBM3e type) combines across GPUs. This creates a unified “memory pool” large enough to fit trillion-parameter AI models entirely in GPU memory. No more stopping training to fetch data from slow storage.
Here’s how key NVIDIA H200 features enhance the NVIDIA DGX BasePOD™:
| Feature |
Impact on BasePOD™ |
| 141GB HBM3e Memory |
Fits entire 70B-parameter models in GPU memory. Eliminates partitioning and reduces checkpointing. |
| 4.8TB/s Memory Bandwidth |
Speeds up data loading for generative AI (text, images, video) by 2.2x vs. H100. |
| FP8 Tensor Cores |
Doubles training throughput for mixed-precision workloads compared to A100 GPUs. |
4. What Are the Architectural Pillars of NVIDIA DGX BasePOD™?
The NVIDIA DGX BasePOD™ delivers reliable, high-performance AI by combining four optimized layers into one cohesive system. Each layer is pre-tested to work perfectly with the others, eliminating guesswork. This integrated approach is key to its success for enterprise AI.
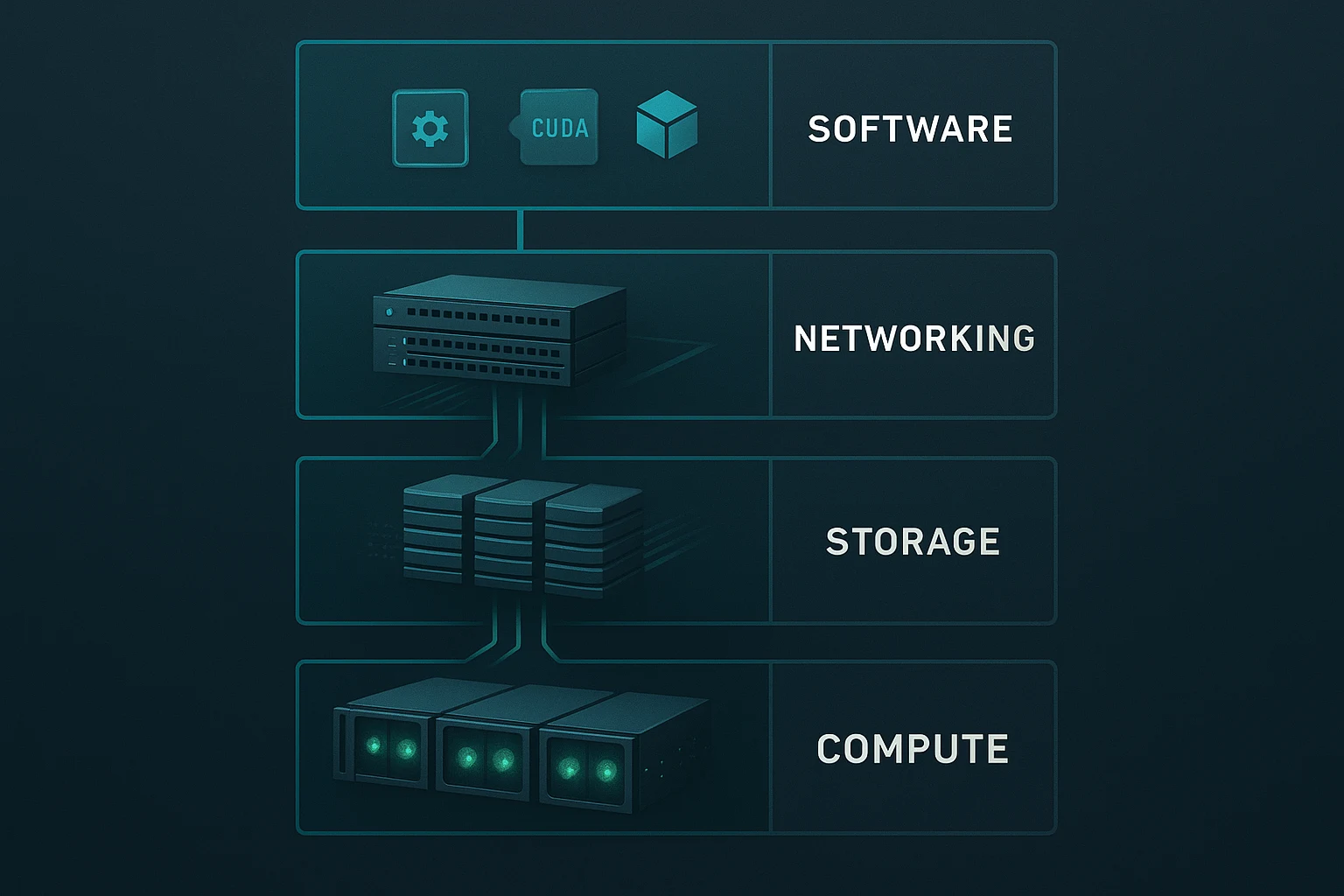
- Compute: The Compute layer uses powerful NVIDIA DGX systems, like those equipped with the latest NVIDIA H200 GPUs. These systems act as the brain of the operation. A key feature is “unified GPU resource pooling.” This means all GPUs across multiple DGX servers can work together seamlessly as one large resource, sharing tasks efficiently for massive AI projects.
- Networking: The Networking layer ensures data flows smoothly without delays. It uses NVIDIA Spectrum-X Ethernet or NVIDIA Quantum-2 InfiniBand switches. These provide ultra-fast connections and support “GPU-direct RDMA.”
RDMA (Remote Direct Memory Access) allows GPUs in different servers to share data directly, bypassing the CPU for maximum speed. This creates a “lossless” network, meaning no data gets stuck or dropped.
- Storage: For storage, the NVIDIA DGX BasePOD™ employs high-speed solutions. It uses parallel file systems like Lustre or WEKA. Think of these as systems that let many computers access storage simultaneously. Combined with NVMe storage tiers – which are extremely fast solid-state drives – it delivers massive throughput. The architecture supports over 60 TB/s, ensuring data-hungry AI jobs never wait for information.
- Software: The software layer ties everything together. It includes NVIDIA Base Command Manager for easy cluster management, CUDA (the programming model for NVIDIA GPUs), and NGC containers (pre-built, optimized software packages). This software stack handles scheduling workloads, managing users, and monitoring system health automatically.
Beyond the core layers, the NVIDIA DGX BasePOD™ includes enterprise-grade features:
- Zero-Trust Security: Strictly verifies every user and device before granting access.
- Multi-Tenant Isolation: Safely runs projects from different teams on the same hardware without interference.
- Automated Monitoring: Continuously checks system performance and health, alerting admins to potential issues.
Here’s a summary of the key components:
| Layer |
Technology |
Function |
| Compute |
DGX H200 Systems |
Provides powerful GPU processing; pools resources across servers. |
| Networking |
Quantum-X/Quantum-2 Switches |
Ensures ultra-fast, lossless data transfer between GPUs and storage. |
| Storage |
Enterprise NVMe Storage |
Delivers massive speed (60+ TB/s) for AI datasets. |
| Orchestration |
Base Command Manager |
Manages resources, users, jobs, and monitors the entire cluster easily. |
5. How Does DGX BasePOD™ Simplify Enterprise AI Deployment?
Deploying enterprise AI infrastructure is notoriously complex and time-consuming. The NVIDIA DGX BasePOD™ radically streamlines this process. It provides a proven path to operational AI, removing traditional barriers.
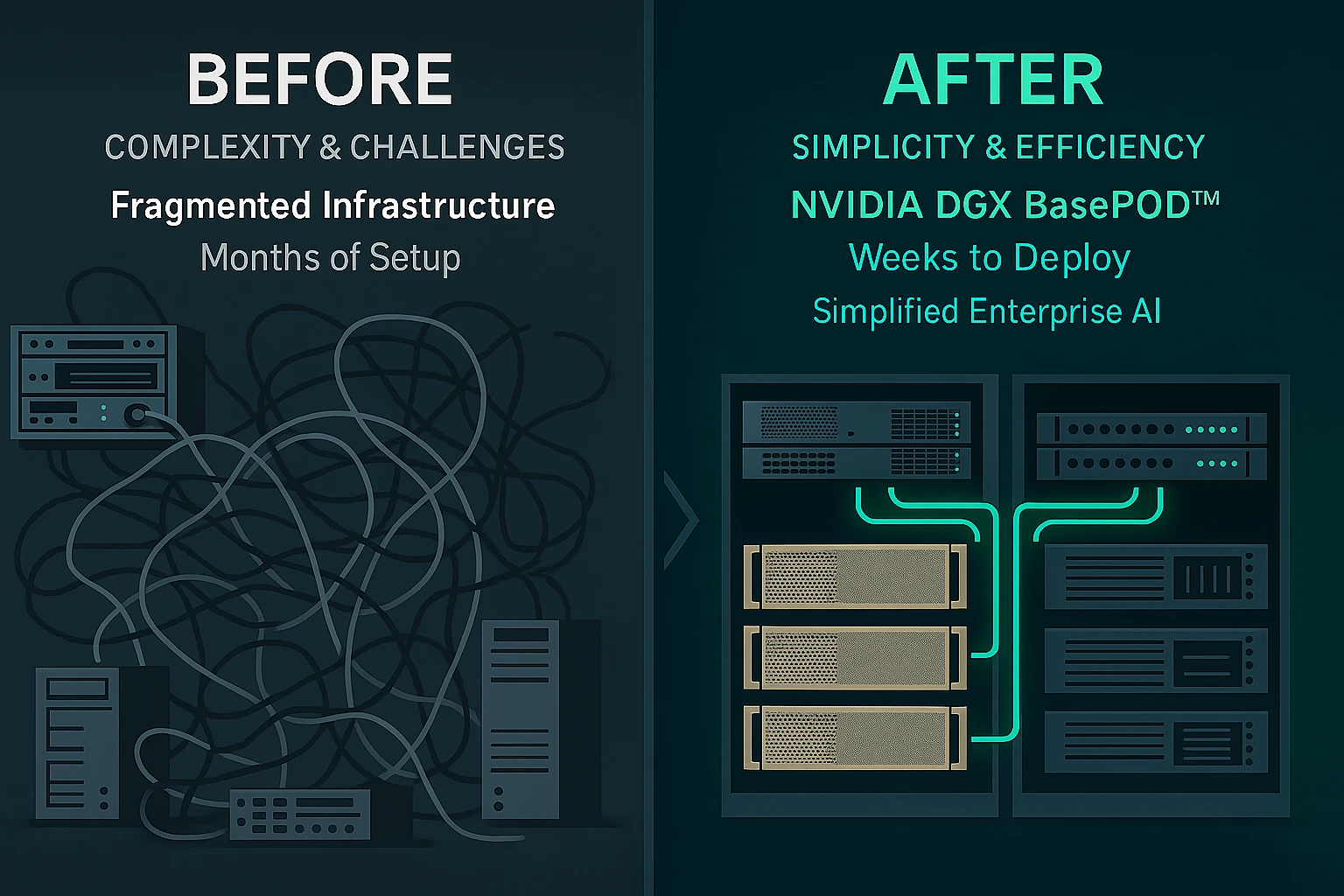
- Pre-Validated Blueprints: Pre-validated blueprints are the foundation. NVIDIA rigorously tests every component in the NVIDIA DGX BasePOD™ architecture. This includes hardware compatibility, software stability, and performance against industry benchmarks like MLPerf. MLPerf measures how fast AI systems train models. Partners like Dell, Lenovo, and Supermicro certify these blueprints for their hardware. You get a ready-made, guaranteed solution.
- Automated Provisioning: Automated provisioning slashes setup time. Using NVIDIA Base Command Manager software, IT teams can deploy a fully functional NVIDIA DGX BasePOD™ cluster in less than one day. Base Command Manager handles the complex configuration steps – installing software, setting up networks, and integrating storage – automatically. This eliminates manual errors and weeks of labor.
- Scalability: Scalability is built-in. Enterprises can start small with just four DGX systems, perhaps with 32 GPUs. As AI projects grow, the NVIDIA DGX BasePOD™ design allows seamless expansion. You simply add more validated DGX units to the cluster. It scales linearly to over 100 nodes (thousands of GPUs) without needing costly redesigning or re-engineering. The blueprint ensures performance grows predictably.
6. What are the Real-World Applications of NVIDIA DGX BasePOD™
The NVIDIA DGX BasePOD™ isn’t just theoretical – it powers groundbreaking AI across industries. Its scalable, reliable design tackles some of the world’s most demanding computational challenges. Here’s where it makes a tangible difference.
- Generative AI: Generative AI thrives on the NVIDIA DGX BasePOD™. Companies use it to train massive foundation models – the core AI systems behind tools like chatbots or image generators. For example, healthcare firms can train models on medical data to discover new drugs. Financial institutions can build models to detect fraud or forecast markets. The BasePOD™’s unified infrastructure handles the enormous data and compute needs reliably.
- Industrial Digital Twins: Industrial digital twins are another key use. A digital twin is a virtual replica of a real-world object, system, or process, like a factory or a car engine. Using NVIDIA Omniverse software on the NVIDIA DGX BasePOD™, engineers can run complex simulations enhanced by real-time AI. This allows predictive maintenance, design optimization, and safer testing before physical changes are made.
- Research: In research, the NVIDIA DGX BasePOD™ can accelerate discovery at exascale. Exascale means performing a billion billion calculations per second. Climate scientists use it to model global weather patterns with unprecedented detail, improving forecasts. Biologists leverage its power for drug discovery, simulating how molecules interact to find new treatments faster than traditional methods.
Conclusion
The NVIDIA DGX BasePOD™ delivers a future-proof foundation for enterprise AI. It eliminates infrastructure complexity while providing predictable scalability – from small pilot projects to massive, thousand-GPU deployments. By integrating cutting-edge components like the NVIDIA H200 GPU, with its massive 141GB memory and ultra-fast 4.8TB/s bandwidth, the BasePOD™ unlocks unprecedented performance for demanding workloads like large language models and generative AI.
This synergy between optimized architecture and next-generation hardware ensures businesses can deploy AI faster, reduce operational risks, and scale resources efficiently. The pre-validated blueprints and partner ecosystem remove traditional deployment hurdles, turning months of integration work into days.
For enterprises prioritizing AI-driven innovation, the next step is clear:
- Evaluate the NVIDIA DGX BasePOD™ blueprints against your AI roadmap.
- Leverage NVIDIA’s certified partners (Dell, Lenovo, Supermicro) for seamless deployment.
Transform your AI ambitions into production-ready reality, faster.











Unregistered User
It seems you are not registered on this platform. Sign up in order to submit a comment.
Sign up now